C17.1. General description of proposed facilities and systems.
1 High level architectural view – the system and its context
1.1 Actor and use case view – core functionality
Reassignment of .org Top-Level-Domain
Registrar Account Administration
Complaints over Registration rights
1.2 Registry Systems Overview – A Design view
1.2.1 Overview of Registry design
1.2.2 Real time and asynchronous communication between Registry Systems – a latency focus
1.2.3 Component security, vulnerability, and recovery – a QoS focus on the Registry Systems
1.2.4 Geographical distribution of Registry Systems
1.2.5. High level view on Core SRS, Registrar Interface and Monitoring components
1.3 Hardware and network topology of the Registry System – A Deployment View
1.4 Real-time updates – A Process View
2 The details of the Registry system(s) – unwrapping the system Packages
2.1.1 Mapping components to hardware – Deployment view of the Registrar Interface package
Hardware specifications for the Registrar Interface system deployment
2.1.2 Control flow – process view of the Registrar Interface package
2.2.1 Mapping components to hardware – Deployment view of the Core SRS
Hardware specifications for the Core SRS system deployment
2.2.2 Control flow – process view of the Core SRS package
2.3.1 Mapping components to hardware – Deployment view of Update Handler package
Hardware specifications for the Update Handler system deployment
2.3.2 Control flow – process view of the Update Handler package
A – Achieving reliable and efficient updates of DNS information
B – Securing the correctness of DNS information
2.4.1 Mapping components to hardware – Deployment view of the DNS package
Hardware specifications for the DNS system deployment
2.4.2 Control flow – process view of DNS Update
A – Achieving reliable and efficient update of Whois information
B – Securing the correctness of Whois information
2.5.1 Mapping components to hardware – Deployment view of Whois
The Whois Public Interface Update
Hardware specifications for the Whois system deployment
2.5.2 Control flow – process view of Whois
2.6 The Automated Consistency Validation System
The Automated Consistency Validation subsystems
Hardware specifications for the Automated Consistency Validation system deployment
2.6.2 Control flow – process view of the Automated Consistency Validation
Black holes: Corrupted service objects that can never be tested
2.8.1 Mapping components to hardware – Deployment view of the Reporting package
Hardware specifications for the Reporting system deployment
2.8.2 Control flow – process view of the Reporting package
2.9.1 Mapping components to hardware – Deployment view of the Offsite Logging package
Hardware specifications for the Offsite Logging system deployment
2.9.2 Control flow – process view of the Offsite Logging package
Hardware specifications for the Offsite Escrow system deployment
2.11.1 Mapping components to hardware – Deployment view of the System Status Supervisor
2.11.2 Control flow – process view of the System Status Supervisor package
2.11.3 Mapping components to hardware – Deployment view of the Error Handler package
2.11.4 Control flow – process view of the Error Handler package
Structural attributes of Hosting Centre
Multiple Server locations and bandwidth providers
Triple database servers and centralized database storage
Hardware encrypted communications with Registrars and external DNS servers
Focus on top class hardware, standardized on few different products from solid vendors
Other miscellaneous provisions of the hosting center
Table of figures and Tables
Figure 1: Use Case top-level diagram
Figure 2: Detailed view of Object Handling use case
Figure 3: Activity diagram realizing the Add Object use case, activity view
Figure 4:Activity diagram realizing the Modify Object use case, activity view
Figure 5:Activity diagram realizing the Remove Object use case, activity view
Figure 6:Activity diagram realizing the TransferDomain use case, activity view
Figure 7 Detailed view of Registrar Account Admin use case
Figure 8: High-level system view, static view
Figure 9: Diagram illustrating latency in the Registry System
Figure 10: Geographical distribution of the system
Figure 11: High level system view with emphasis on complexity
Figure 12. Diagram showing the Registrar Interface Subsystem
Figure 13. Decomposition of the Core SRS package
Figure 14 presents the logical distribution of responsibilities among the subsystems
Figure 15. Decomposition of System Monitoring Package
Figure 16. Geographical distribution of GNR main site, DR site and regional sites
Figure 17: Simplified network diagram for regional sites
Figure 18: Network deployment for regional DNS site
Figure 19: Simplified physical network diagram for main site in UK
Figure 20: Main UK site hardware deployment
Figure 21: The Update process of the resolving services
Figure 22: Decomposition of the Registrar Interface package, system view
Figure 23: The Registrar Interface, deployment view
Figure 24: Control flow for the Registrar Interface, transaction request.
Figure 25: Decomposition of the Core SRS package, system view
Figure 26: The Core SRS, deployment view
Figure 27: Control flow for the update of Core SRS
Figure 28: Control flow Core SRS Update, Update process
Figure 29: The MQ Message format
Figure 30: Decomposition of the Update Handler package, system view
Figure 31: The Update Handler, deployment view
Figure 32: Control flow for the Update Handler
Figure 33: Decomposition of DNS Update, system view
Figure 34: The DNS Update, deployment view
Figure 35: Control flow for DNS Update process, Local Update Handler to Master DNS Server
Figure 36: Control flow for DNS Update process, Master DNS Server to Slave DNS Servers
Figure 37: Decomposition of the Whois service, system view
Figure 38: Whois Update and escrow, deployment view
Figure 39: Control flow in the Whois Update process
Figure 40: Control flow in the Whois escrow process
Figure 41: Decomposition of Automated Consistency Validation System, system view
Figure 42: Deployment diagram for the Automated Consistency Validation System
Figure 43: Control flow in the Automated Consistency Validation System
Figure 44: Transaction object state in the ACV process
Figure 45: High-level system view for the Billing package
Figure 46: Decomposition of the Reporting package
Figure 47: The Reporting system, deployment view
Figure 48: Control flow for the Reporting process
Figure 49: The Offsite Logging System and its dependent packages
Figure 50: Replication of databases, inter-site and inter-continental
Figure 51: Offsite Logging, deployment view
Figure 52: Control flow for Offsite Logging
Figure 53: Decomposition of the Offsite Escrow, system view
Figure 54: Decomposition of the System Monitoring package
Figure 55: An overview of the System Monitoring architecture
Figure 56: Control flow for System Monitoring
Figure 57: Example of MRTG generated graph
Figure 58: : Example of RRDtool generated graph
Figure 59: The Error Handler, deployment view
Figure 60: Control flow for the Error Handler, process view
Figure 61: The table structure of the Authorative Registry Database
Figure 62:geographical spread of GNR locations
This chapter presents the systems and technical facilities that will constitute Global Name Registry’s .org Registry. The first part of this chapter takes a high level view of the Registry and its interfaces, and employs use-case modeling to describe the interactions and operations to ensure that Registry performs on a high level, as well as going on to show the high level network diagrams and hardware topology diagrams.
The second part of this chapter is describing in more detail the logic and processes that are key to operating the Registry. Through sequence diagrams, deployment diagrams and hardware structure, readers can take a comprehensive look into the design of the Registry. While some parts of the Registry system is explained in greater detail in Sections C17.2 to C17.16, C17.1 is meant to be comprehensive and give the reader good insight into how the proposed .org Registry will work.
Thus, Section C17.1 describes the basis for the Registry functionality that:
1. Is a world-wide fully self-operated DNS network, capable of serving more than 200,000 queries per second, or 17.2 billion queries per day. More capacity can be easily added to scale the capacity almost linearly.
2. Contains a centralized Whois source for .org, capable of serving more than 300 queries per second, or 26 million queries per day. More capacity can be easily added to scale the capacity on a roughly linear basis.
3. Features a Registry connected to all ICANN Accredited Registrars through EPP while simultaneously supporting the legacy RRP for their convenience during a long period.
4. Features a Shared Registry System capable of supporting potentially hundreds of Registrars, with up to 1500 database transactions per second, or 129 million transactions per day. The system is designed to be able to add more capacity when necessary.
5. Features updates to the DNS and Whois service contents seconds or minutes after database updates happen.
6. Contains a fully redundant system that can fail over to a disparate location in emergencies without significant loss of service.
The figure below presents the Registry System and the users who utilize the services it offers, or who interact with the Registry System by other means. In this section the users (actors) are described, as well as how they can use the Registry System (use cases). The realization of the Registry System is presented in subsequent subsections according to design, physical deployment, and process.
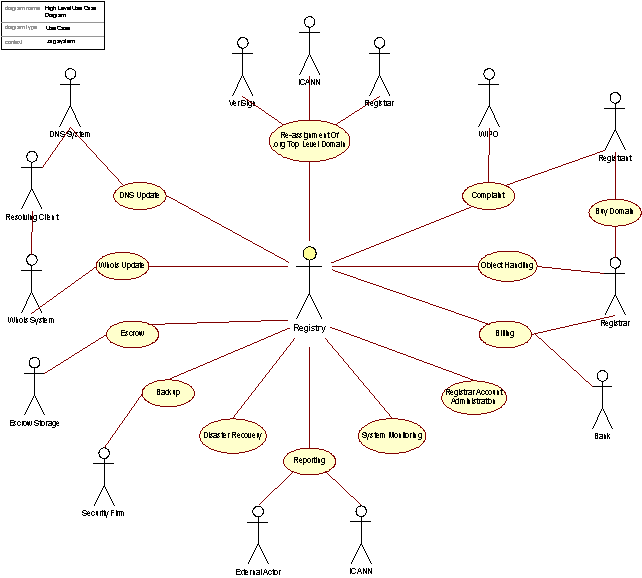
Figure 1: Use Case top-level diagram
1.1 Actor and use case view – core functionality
The actors presented in Figure 1 directly interact with the core Registry System.
Actor descriptions
The core functionality of the Registry System is centered within the Registry. The Registry administers one or more top-level domains (e.g. .org). All main use cases are in some way involved in the handling of these top-level domains. In the following discussion, we will give a brief description of all the main actors and use cases identified in Figure 1.
Actors:
|
|
Registry: This is the organization responsible for administering one or more top-level domains. By organization we mean the technical as well as organizational infrastructure built to support this business.
|
|
|
Registrar: A Registrar is an organization acting as a domain buyer on behalf of a Registrant. The Registrar is responsible for the technical maintenance of domains bought from a Registry. Only Registrars may add, edit or delete objects from a Registry.
|
|
|
Registrant: The Registrant is the actual buyer of a domain. The registrant has no direct contact with the Registry. All actions concerning domains are directed towards a Registrar.
|
|
|
VeriSign: VeriSign is the registry currently administering the .org top-level domain. The .org TLD is to be transferred a new registry, symbolized by the Registry actor. |
|
|
Bank: A financial institution responsible for handling the monetary transactions involved in the process of billing Registrars. |
|
|
ICANN: The Internet Corporation for Assigned Names and Numbers (ICANN) is a non-profit, private-sector corporation. ICANN is dedicated to preserving the operational stability of the Internet. ICANN coordinates the stable operation of the Internet's root server system. |
|
|
WIPO: The World Intellectual Property Organization will be involved in arbitration between conflicting domain name Registrants under the UDRP. |
|
|
External Actor: By External Actor we mean organizations that should receive reports from the Registry, other than ICANN or WIPO. |
|
|
Security Firm: The Security Firm is responsible for transporting and handling backup-tapes that are to be transported off-site. |
|
|
Escrow Storage: Escrow is a holding of critical data by a trusted third party, the Escrow Storage firm. The data is held to be transferred to an entity external to the Registry in case of special events. The Escrow Storage firm is responsible for storing and protecting the escrowed data and will release the data to the relevant party upon triggering of predetermined conditions. |
|
|
DNS-system: The DNS-system is the authoritative name server system for the top-level domain(s) administrated by the Registry. |
|
|
Whois-System: A service providing information on registered domains handled by the Registry. The Whois system for .org is currently handled both by the Registry (“thin” part) and the Registrars (“thick” part, where contact information is included). |
|
|
Resolving Client: Application using resolving services (e.g. DNS System and Whois System). |
Use case descriptions
Reassignment of .org Top-Level-Domain
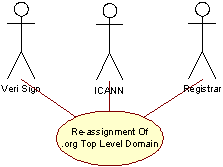
This use case represents the process of transferring the .org top level domain from the current registry VeriSign, Inc. to The Global Name Registry, Limited (“GNR”). The process of transferring has both technical as well as non-technical challenges. Focusing on the technical aspects one has to aim at minimizing service down-time due to the physical relocation of the registrar services, and assure 100% data consistency across the transferal –i.e. no information necessary for the proper operation of the registry services must be lost due to the transfer.
At a softer, more non-technical level, there are challenges associated with the infrastructural changes that an operation of this kind represents. More than 100 registrars have to update their registrar systems for use with the new registry. Changes in routines and processes at different organizational levels have to be implemented. The registrars will have to be re-accredited by the new registry and adapt to the major or minor differences between the old and the new registries’ ways of operating. GNR aims to minimize these differences and transition challenges for external parties. The Registry Transition is described in more detail in Section C18 in this .org Proposal.
Object Handling
The Object Handling use case is an abstraction of all operations resulting from interaction between the Registry and a Registrar concerning an object. An object in this context may be a domain, a contact, a DNS server or other information accessible and modifiable by Registrars. See section C17.3 – Database Capabilities, for details regarding object types and their handling. Object Handling is further refined in the following use case diagram:
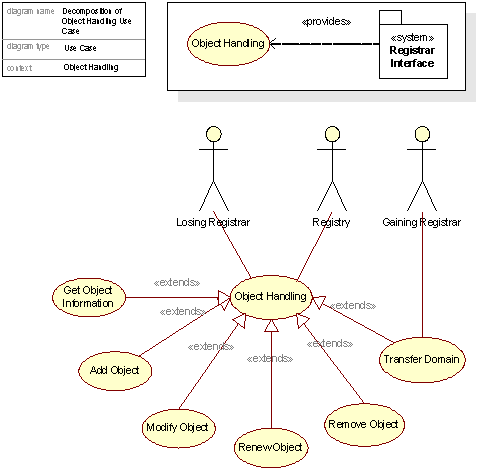
Figure 2: Detailed view of Object Handling use case
Add Object
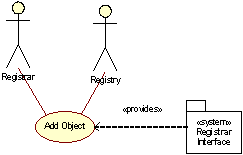
This use case describes the process of object registration. It is initiated by a Registrar who seeks to add an object of some kind, typically a domain with associated DNS server and contacts (in case of a thick registry). The activities typically involved in this process are shown in the figure below, which gives a high-level description of the control-flow when adding new objects.
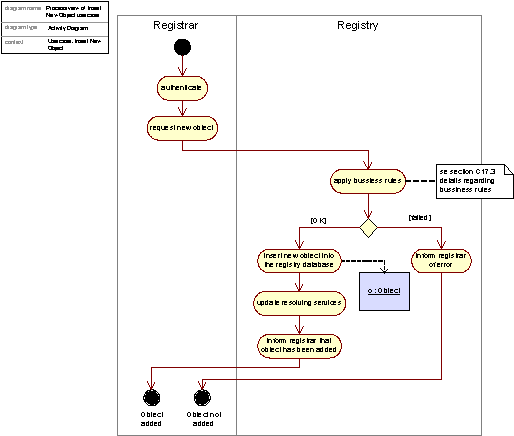
Figure 3: Activity diagram realizing the Add Object use case, activity view
The add domain object operation is a billable transaction and will in addition to the steps identified above trigger the Billing use case.
Modify Object
A Registrar may change information about an object, such as status, expiration date, name servers handling a domain, or contact info. Registrars may only access and update domains they already own. The activities typically involved in this process are shown in the figure below.
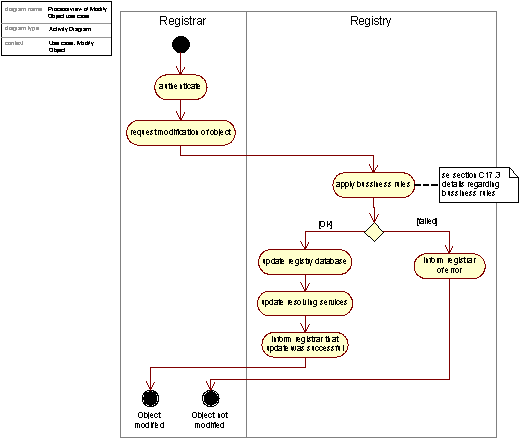
Figure 4:Activity diagram realizing the Modify Object use case, activity view
Remove Object
A Registrar may delete an object registered by that Registrar. The activities typically involved in this process are visualized in the following Figure, which gives a high-level description of the control-flow when deleting domains.
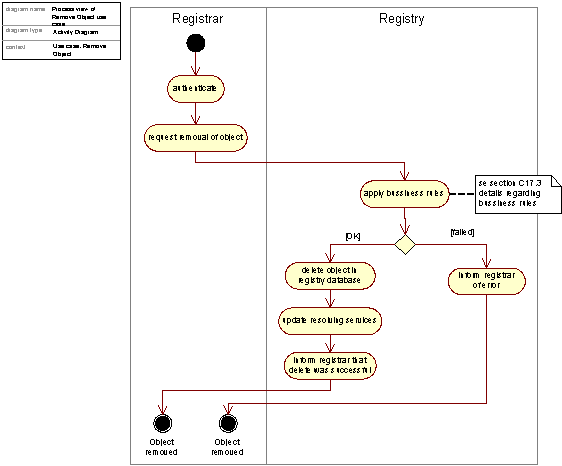
Figure 5:Activity diagram realizing the Remove Object use case, activity view
Transfer Domain
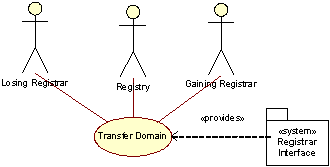
A domain object may be transferred between two Registrars. This may only happen if the Registrant owning the domain gives the new Registrar permission to take over the domain in question, or in the case of UDRP arbitration or otherwise conflict handling/arbitration by the Registry.
The transfer process is to a certain extent protocol-dependant. The RRP and EPP protocols each support the Transfer in a different way. As an example, under EPP, each object is assigned a password which must be used to complete a Transfer. More information on RRP, EPP, and transfer handling can be found in Sections C17.2 (RRP and EPP implementations), C22 (RRP to EPP migration) and C17.3 (database and business rules).
The activities typically involved in the Transfer process are shown in the following figure.
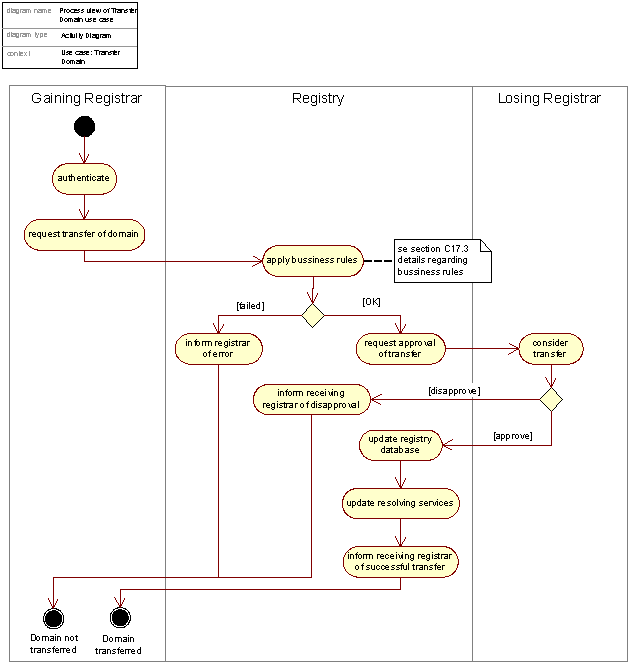
Figure 6:Activity diagram realizing the TransferDomain use case, activity view
Buy Domain
This use case is an abstraction of the process a Registrant undertakes when applying for a domain. The Registrant asks the Registrar to carry through the use case Insert New Domain for a given domain. Therefore, Buy Domain is a use case that only indirectly utilizes the Registry System. The communication with the Registry System is restricted to accredited Registrars.
The Registrant may use the WHOIS service provided by the Registry to check if a domain name is taken or not. The only way a client may apply for a domain is through a Registrar. The only situation a Registrant will be in direct contact with a Registry is in case of domain name dispute (see the Complaint use case).
GNR strives to inform potential Registrants globally about the benefits of buying a domain for their own purposes. Through direct marketing practices and co-marketing activities with Registrars and promotions, GNR seek to increase growth of the TLD it operates. A fuller discussion of proposed GNR marketing activities for .org can be found in Section C38 and other parts of this .org Proposal.
Billing
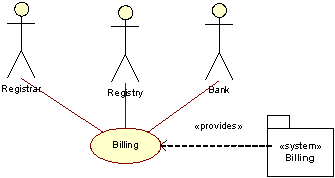
The prime principle of registrations is that the domain name registrations are prepaid, although GNR also grants Registrars a $1000 credit limit.
The Billing use case is a triggered by billable operations (See Sections C25-C27) initiated by a Registrar. The Registry System debits the amount associated with the operation from the Registrar’s Registry account. The Financial Controller, as part of the Registry, handles billing and administers the flow of assets and invoices. The Bank handles the monetary transactions involved.
When a registration is completed, the Registrar’s account balance is debited with the price of one registration. Registrations continue as long as the balance is positive, or the credit limit is exceeded, after which further billable operations will be denied.
Once a month, the Registrar is billed with the amount necessary to restore their credit balance. This amount can be chosen by the Registrar himself and can vary from month to month.
Registrar Account Administration
This use case involves all administration of the individual Registrar accounts. Standard operations as shown in the figure below are supported.
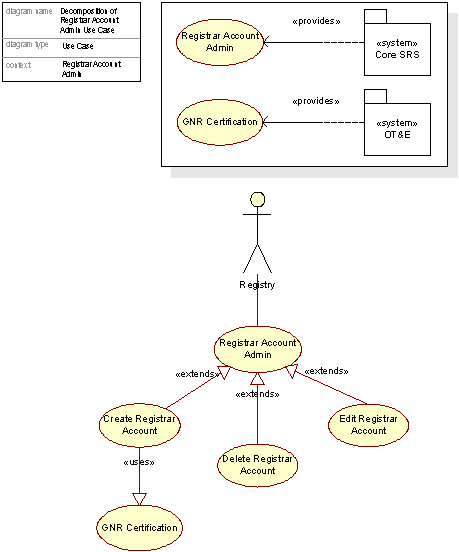
Figure 7 Detailed view of Registrar Account Admin use case
Only ICANN accredited Registrars may be given an account. All existing ICANN accredited Registrars will be invited to also become .org Registrars. There will be no restriction to the number of Registrars.
Registrars that are given an account must also be certified by the Registry. This to assure that the Registrars’ systems are compatible with the Registry System. See section 1.2.1 Overview of Registry design for more details on the OT&E system.
Registrars will have a running relationship to the Registry, mostly for billing and credit purposes. Credit for registrations can be updated at any time.
Reporting
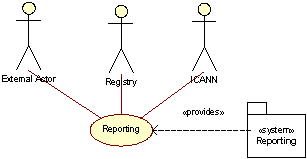
GNR provides a number of reports to ICANN on the status of the Registry, to Registrars on their respective statuses, and to the general public.
Most reports are automatically generated by the Reporting system and are distributed by means of FTP or mail.
Complaints over Registration rights
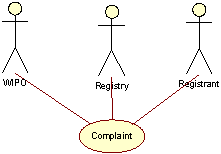
The Registry will not perform arbitration of disputes. UDRP disputes and other forms of arbitration between Registrants in general will be handled by a third party, e.g. WIPO.
Backup
Backups are taken periodically and transported off-site by a security company. See Section C17.7 for further descriptions of Backup.
Escrow
Approximately once a month a copy of the registry database will be sent to a secure storage place offsite. There is also a separate Whois escrow intended for future use.
DNS Update
A DNS Update is triggered by an operation from the Registrar. When an operation on an object is executed in the Core SRS, the Registry System will propagate the changes to affected Resolving Services through the Update Handler. We use BIND9, developed by ISC, which supports the DNS extensions necessary to allow Incremental Zone Transfers (IXFR). At each regional site there is a stealth master DNS server, which will be dedicated to doing updates to the slave DNS servers with the AXFR and/or IXFR mechanisms of DNS.
Secure network connections between main and regional sites and use of point-to-point authentication and integrity checking according to RFC2845 (also referred to as TSIG) is employed to ensure that the data arrives at the intended destination without tampering or sniffing on the way.
Whois Update
The Whois Update use case is quite similar to the DNS Update use case. The Whois use case is triggered by the operation on an object in the Core SRS that in turn has to be reflected in the Whois system. These operations may concern domains, contacts, name servers, registrars, or other objects that may exist in Whois system.
Whois updates are distributed to the regional Whois system(s) by the Update Handler.
1.2 Registry Systems Overview – A Design view
1.2.1 Overview of Registry design
The design view of the Registry System encompasses the systems and collaborations that form the vocabulary of the solution. This view primarily supports the functional requirements of the system, meaning the services that the system should provide to its end users.
The figure below shows a high-level system view of the Registry System. The packages are systems within the Registry System dependent on each other and are responsible of implementing distinct services. The figure is a logical presentation of the Registry System.
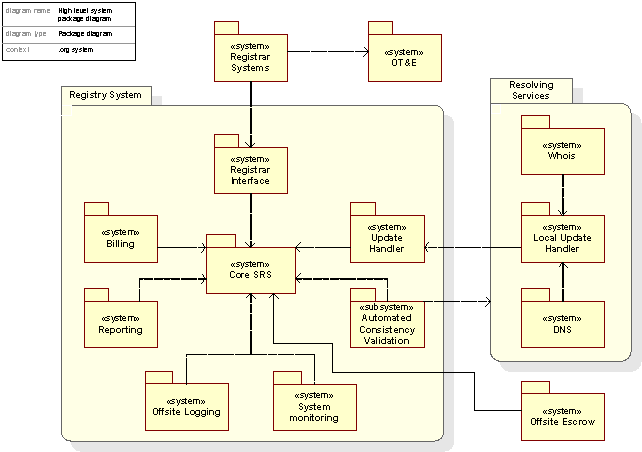
Figure 8: High-level system view, static view
A brief description of each of the packages:
Registrar Systems. The systems held by the registrar at the registrar’s site are enabled to communicate with and operate against the Registry System. These systems will not be elaborated in more detail in this document, but it is worth noting that the transition to a new registry for most registrars will imply changes into their systems. See Section C18 for further discussion regarding the transition process and its implication for registrars.
Registrar Interface: The registrar systems’ interface to the Registry System. Registrars use either the Registrar-Registry Protocol (RRP) or the Extensible Provisioning Protocol (EPP) for communication with the Registry System.
OT&E : Each Registrar must prior to operations in the SRS demonstrate basic functional skills in the Operational Test & Evaluation (Ot&E) Environment. This environment is functionally identical to the SRS, with the exception that no data in the OT&E will result in changes to resolution services or similar. All data in the OT&E only reside in the OT&E database and are used for the purpose of training Registrars to operate in the SRS. Operators can age data, delete data and replace data in the OT&E as part of the Registrar training.
Core SRS is the central unit of the Registry System, where the business logic and the authoritative database are held. The Core SRS is the most critical part of the system, on which all other systems in the Registry System are dependent.
System Monitoring: The system that provides facilities to supervise the Registry System and its operations, as well as Error Handling.
Billing: The system managing billing of billable operations performed by the registrars.
Reporting : The reporting system creates and manages reports to ICANN, Registrars and third parties.
Automated Consistency Validation is a system verifying that information provided by the Resolving Services are consistent with information stored in the Authoritative Registry Database in the Core SRS. This advanced feedback system allows GNR to update resolution services in real time.
Offsite Logging is a system providing archive logs from all transactions performed.
Offsite Escrow: The system providing the escrow of the Authorative Registry Database in the Core SRS at a secure, offsite location.
Update Handler. A system responsible for routing and distributing changes made to the Authoritative Registry Database in the Core SRS to the parts of the Registry System and Resolving Services that are to receive the changes on a near real-time basis.
Resolving Services: The resolving services encompass public services like Whois look-ups and DNS resolving services. A local Update Handler is responsible for propagating messages to local message consumers, i.e. the DNS system and the Whois system.
What follows is a set of focused views intended to present some critical aspects of the Registry System at a high-level of abstraction. Subsequent subsections will go into greater detail at a lower system level when such details are not described in other sections.
1.2.2 Real time and asynchronous communication between Registry Systems – a latency focus
This subsection is focusing on message paths in the system and associated latency in the Registry System. This is visualized in the figure below. The primary cause of latency in the system is the use of message queues. Message queues are used throughout the system to facilitate scalability, robustness, congestion control, and separation of concern among system components.
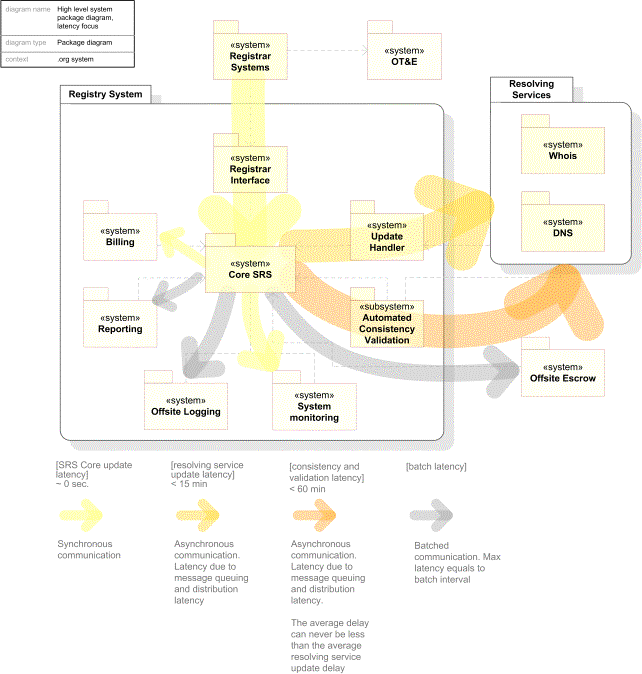
Figure 9: Diagram illustrating latency in the Registry System
From an Internet-availability and stability point of view there are two message paths that deserve special attention: the path (A) associated with the process of updating objects, starting with a registrar issuing a request (e.g. new domain request) and ending in the updating of the affected resolving services (e.g. DNS and Whois). The second path (B) is related to the first, but takes as its starting point the committed transaction in the Core SRS resulting from the registrar’s original request and ends in the validation of the changes made in the resolving services.
|
Path A – Registrar System à Resolving Service - latency introducing steps |
||
|
Sender |
Receiver |
Latency |
|
Registrar system |
Core SRS |
No latency. Synchronous communication |
|
Core SRS |
Update Handler |
Potential point of latency. The Core SRS contains a process (Update Message Generator) that is responsible for propagating committed transactions from the Authoritative Registry Database to the update handler. In situations with near congestion load on the Authoritative Registry Database the Update Message Generator may delay its polling for new transactions to reduce the overall Core SRS load. |
|
Update Handler |
Resolving Services |
Potential point of latency. The update handler holds a queue for incoming messages reflecting changes in Core SRS, and outgoing queues for each message consuming system component (e.g. DNS, Whois). Depending on consuming components’ throughput capacity messages may be delayed at this stage. |
|
Path B – Core SRS à Resolving Service - latency introducing steps |
||
|
Sender |
Receiver |
Latency |
|
Core SRS |
Automated Consistency Validation |
Potential point of latency. The Core SRS never sends anything to the ACV, but the ACV pulls information out of the QA database. Since it bases its process on the messages in the message queue of the Update Handler, there may be the same latency in this process as for the Core SRS-Update Handler path. |
|
Automated Consistency Validation |
Resolving Services |
Potential point of latency. The Automated Consistency Validation process will start trying to verify the consistency of the resolving services affected by the message in question after a initial minimum delay (to give the resolving services time to process the message). On resolving error, the system will wait for an additional period time before retrying. This process is repeated until a maximum probable path A latency limit is reached. To sum up: the Path B latency will never be less than the Path A latency. One has to define a maximum probable latency for Path A as a threshold for when update messages not reflected in Resolving Services are to be treated as lost. |
The other paths illustrated in the figure above can be partitioned into synchronous communication and batched communication.
|
Synchronous communication |
|
Path |
|
Core SRS à System Monitoring. The monitoring system provides real time information about system statuses, not only for Core SRS but also for all other systems that have monitoring extensions. |
|
Core SRS à Billing. Billable operations are immediately reflected in the billing system |
|
Batched communication |
|
|
Path |
Batch Interval |
|
Core SRS à Offsite Escrow. The Core SRS uploads the escrow files to the Offsite Escrow storage at a regular interval |
Every day, at given hour |
|
Core SRS à Offsite Logging. Core SRS logs are transferred offsite at regular intervals |
Continuous and in addition, monthly batch checking
|
|
Core SRS à Reporting Analyses are collected, and reports are generated at regular intervals. |
Monthly |
1.2.3 Component security, vulnerability, and recovery – a QoS focus on the Registry Systems
GNR operations teams and customer support teams are the most important feedback loops internally in GNR to protect the registry system. Problems can be detected at many levels but with very few (and non-critical) exceptions, historically, problems have been detected by GNR testing, quality control processes or operational problem detection and monitoring.
In addition to this problem detection, GNR has committed effort to ensure a reliable and secure system. The items list below enumerates such efforts (See Section C17.9 and Section C17.14 for further descriptions):
Security
· Registrar security and authentication
· Data Protection Procedures
· Software security procedures
· Software diversity
· Hardware encrypted communications with Registrars and external DNS servers
· Firewalls
· Intrusion Detection Systems
· Encrypted channels to protect network
· Jump points
· Alert systems
· Log and monitoring systems
· Assured Asynchronous communication with MQ
Environmental security
· Facility security including access control, environmental control, magnetic shielding and surveillance
· Human Security policies
· Security of offices and employees
Vulnerability
· Redundant power systems
· Redundant network
· Proven software and operating systems
· Multiple server locations
· DNS servers on different backbones, and with software diversification, running two different versions of resolution software at all times
Recovery
· Daily backups that are transported offsite
· Disaster recovery site
· Triple database servers and centralized database storage
· Continuous log of database transactions transported offsite
· Mirrored, backed up storage for all data and software
· Top class enterprise firewalls Cisco PIX in failover configuration
· High availability active/active failover system on critical systems
· Servers and hard disks in stock, pre-configured and ready to boot from the central storage ESS
Scalability
· Layered architecture makes it possible to linearly scale almost any element in the Registry System
1.2.4 Geographical distribution of Registry Systems
The Registry system is dispersed over three continents and five locations. The main site is in London, UK, where the core Registry System, as well as the Resolving Services are located. The regional sites are located in Norway, Hong Kong, West-US and East-US. At the regional sites, there are local Update Handlers and resolving services. In addition, a Disaster Recovery Site in Norway.
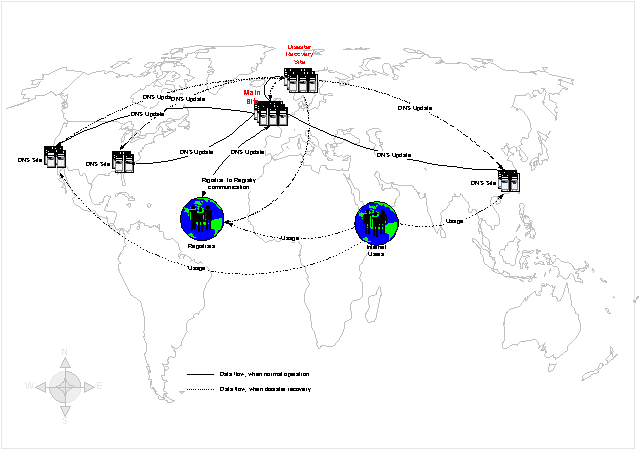
Figure 10: Geographical distribution of the system
1.2.5. High level view on Core SRS, Registrar Interface and Monitoring components
The figure below illustrates the complex portions of the Registry System. These parts are seen as complex due to their enhanced functionality and because the services they offer are critical services. These complex parts will be presented briefly in the subsequent subsections by unwrapping the package and describe the subsystems of which they are built, and in detail in Subsection 2 – The Details of the Registry System(s) – Unwrapping the System Packages.
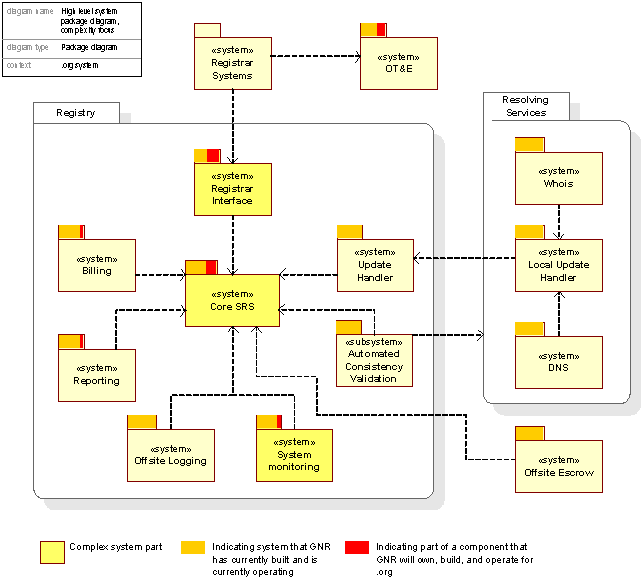
Figure 11: High level system view with emphasis on complexity
The Registrar Interface is complex both in functionality, due to the advanced logic and because of (1) supporting both RRP and EPP initially, and (2) the migration from RRP to EPP.
Core SRS holds complex logic and functionality. System Monitoring is a cluster of systems and tools for monitoring the whole Registry System and is, in that way, complex.
For the operation of .name, GNR provides major portions of the Registry Systems, as described in the executive summaries of this .org application, but in the .org context some additional parts will need to be procured. In the figure above we have indicated parts that are currently not fully developed. This concerns mainly the Registry Interface, which will be migrated from RRP to EPP, and the Authorative Registry Database in the Core SRS, which will be migrated from supporting a thin registry to supporting a thick registry. Please consult Section C17.2 and C17.3 for a detailed description of the proposed protocol handling and data model.
Registrar Interface Package
The Registrar Interface will offer the registrar either an RRP Interface or an EPP Interface corresponding to what protocol the registrar uses. Each subsystem provides functionality for holding sessions, decoding and validating the transactions initiated, and translating the protocol specific commands to the Core SRS API.
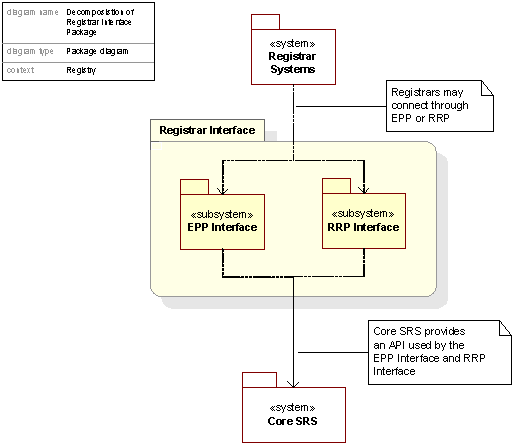
Figure 12. Diagram showing the Registrar Interface Subsystem
Core SRS Package
The figure below presents the subsystems in the Core SRS.
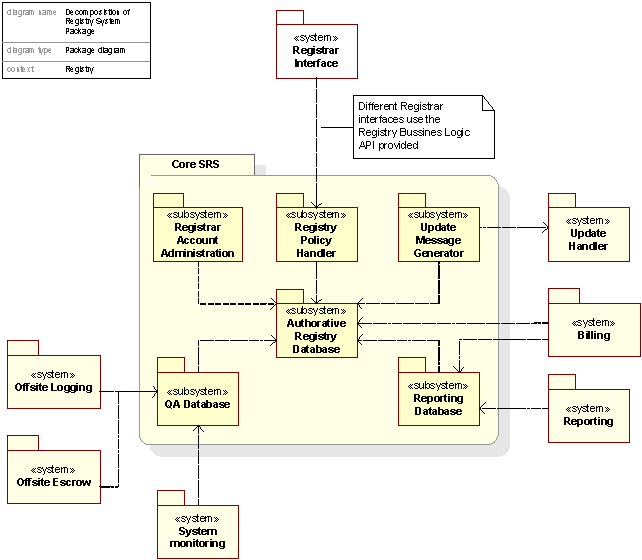
Figure 13. Decomposition of the Core SRS package
The Registry Policy Handler contains the business logic of the Registry System and checks and validates the incoming commands from the Registrar Interface; this is related to consistency on a semantic and business logic level.
The Authorative Registry Database is an Oracle database where consistent datasets are stored. This is the authorative source for the Registry information.
TheQA Database (Quality Assurance Database) is a read-only copy of the Authorative Registry Database used by the Automated Consistency Validation system, by Offsite Logging and Offsite Escrow.
TheUpdate Message Generator is a subsystem that checks the Authorative Registry Database for updates and if any such updates available, translates these into an MQ message and sends them to the Update Handler.
The Reporting Database contains a subset of the Authorative Registry Database in addition to other information related to reporting services.
The Registrar Account Administration is a subsystem by which the Financial Controller can administer the Registrars’ accounts.
The figure below illustrates the distribution responsibility within the Core SRS as a layered system.
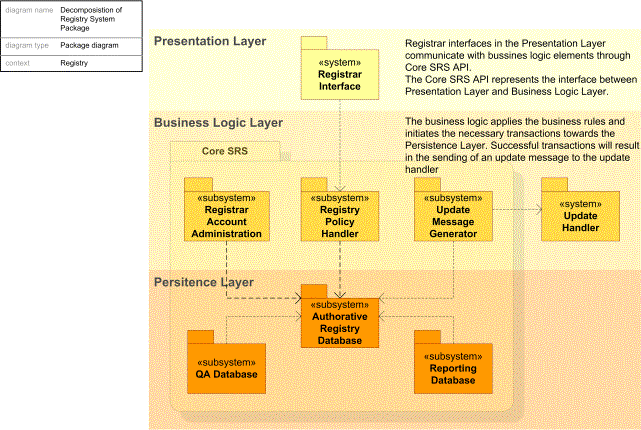
Figure 14 presents the logical distribution of responsibilities among the subsystems
System Monitoring Package
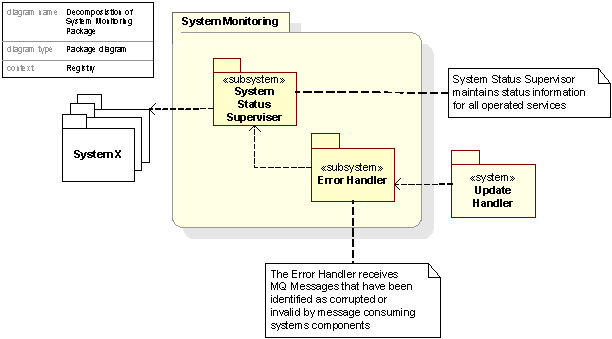
Figure 15. Decomposition of System Monitoring Package
The System Status Supervisor maintains status information for all operated services by means of internal and external monitoring systems and analysis tools, and is therefore not a single system, but a cluster of systems and tools for monitoring the whole Registry System. See Subsection 2.11 – System Monitoring and Section C17.14 for further details.
The Error Handler polls messages that are put on the Error MQ in the Update Handler. The system dumps messages to local dump files, logs the event and sends a warning to the Network Operation Center at UK main site.
1.3 Hardware and network topology of the Registry System – A Deployment View
The hardware topology of the Registry System on which the system executes, and the network connections by which the system is connected internally and externally to the Internet are described in this section.
The Registry System is spread out geographically to provide less latency on services, more reliability and higher redundancy, as the following high level view shows:
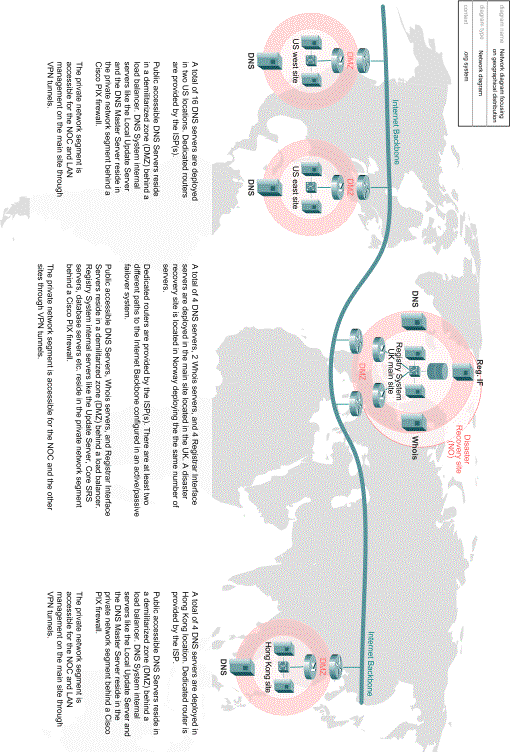
Figure 16. Geographical distribution of GNR main site, DR site and regional sites
Each regional site has a complete set of load balancers, firewalls and routers in active-passive high availability configurations. This ensures security and reliability. All hosting centers operated by GNR have characteristics as described in the Environment section of this Section C17.1. The diagram below is showing in a simplified way how the regional sites are set up:
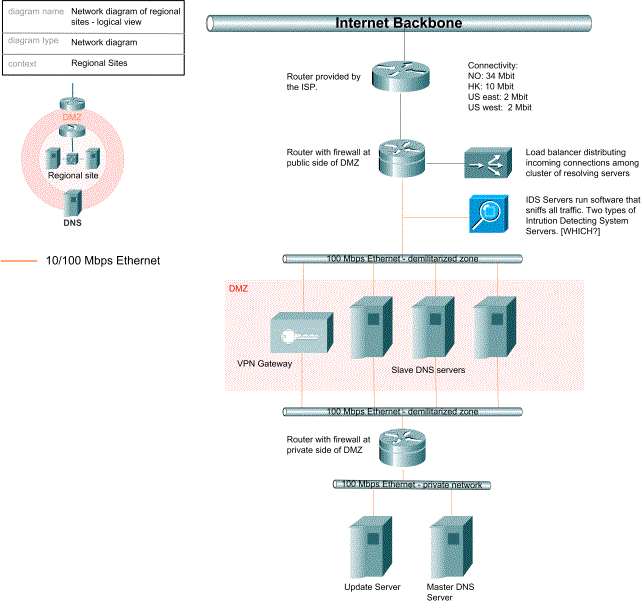
Figure 17: Simplified network diagram for regional sites
This PIX firewalls used by GNR in active-passive mode are state of the art Cisco firewalls. A heartbeat signal is sent from the passive PIX to the active PIX, and in case the active PIX should go down, the passive PIX will instantly become active. Therefore, the firewalls are fully redundant.
GNR uses PIX firewalls on all network borders. For more information about the PIX series and security, please see Appendix 26.
To show the configuration in more detail, and see how the load balancing and active-passive configuration of the load balancers and firewalls provide full service availability even in the case of outage to one firewall, or one load balancer, etc, the diagram below provides more detail:
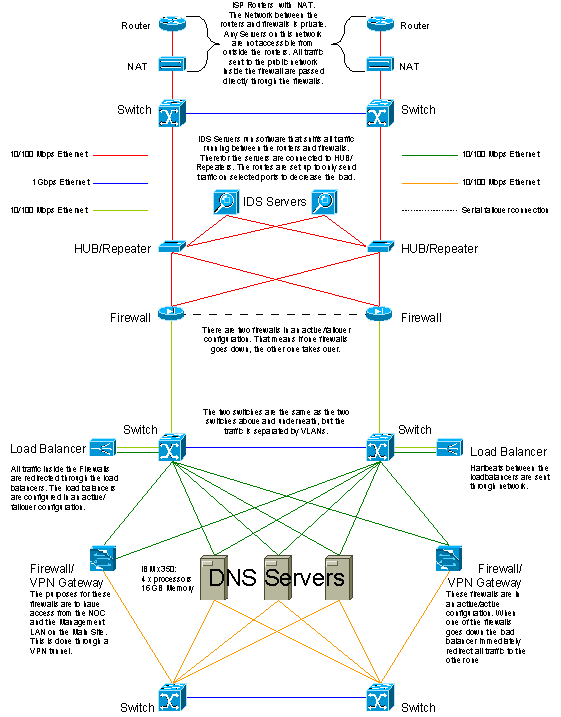
Figure 18: Network deployment for regional DNS site
For the main UK site, GNR uses Foundry switches instead of normal network equipment and routers. The Foundry switching equipment is extreme-high-end switches that has replaced all switches and routers on the internal network. Similar equipment run large scale transaction systems like banks.
More information on the relationship between Foundry and GNR, and the Foundry equipment can be found in Appendices 22, 23 and 24.
The internal network performance of GNR has with the Foundry equipment increased thousandfold and network latency internally is down to 2 microseconds, far below what is possible with ordinary network equipment. The Foundry BigIron 8000 provides internal hardware switching for the internal network, and the connection is physically as shown in the following:
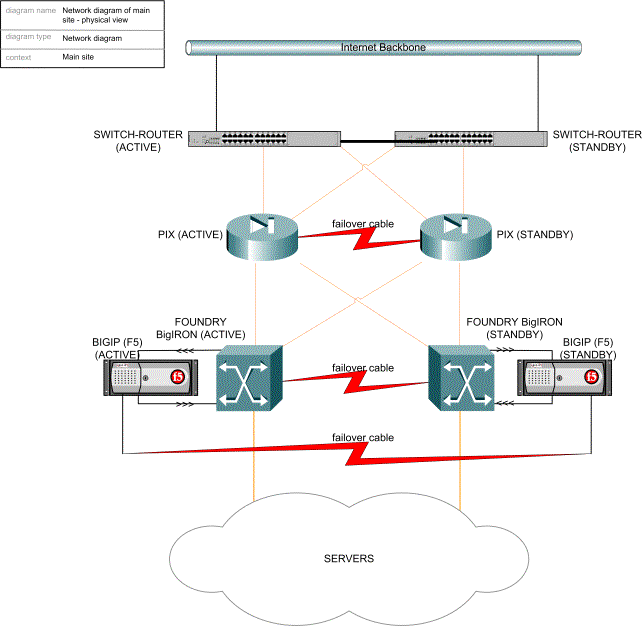
Figure 19: Simplified physical network diagram for main site in UK
The UK main data centre has 3 LANs internally: a public LAN, a De-Militarized zone and a management LAN. All machines have dual network interfaces to ensure that single network card failures do not take down any service. The Foundry equipment provides all connections between LANs. The following diagram is a conceptual view of the network structure internally, illustrating the connections that physically is handled internally by the BigIron.
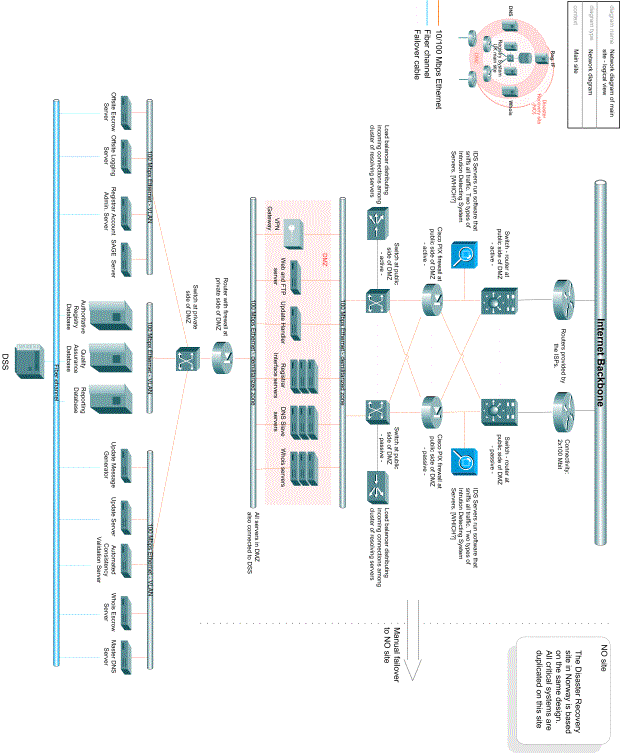
Figure 20: Main UK site hardware deployment
1.4 Real-time updates – A Process View
The update process from Registrar to the Resolving Services is a critical process in order to maintain the superior services of the Registry System. The figure below describes this process in a sequence diagram. The diagram illustrates the flow of control among systems or subsystems involved in an update.
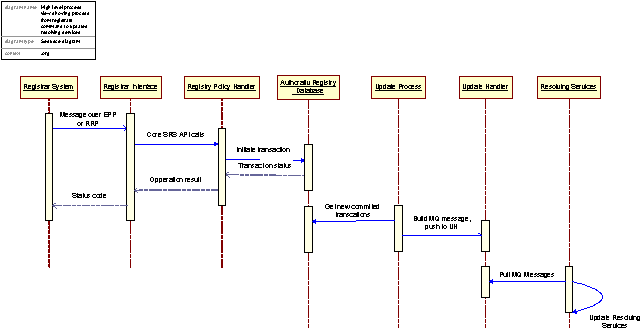
Figure 21: The Update process of the resolving services
This section presents packages described in the previous section in detail, both the high level packages and the packages presented in relation to the complex systems. With basis in Figure 8: High-level system view, static view, we will unwrap each package and present the subsystems of which the packages are constituted, in detail.
2.1 Registrar Interface
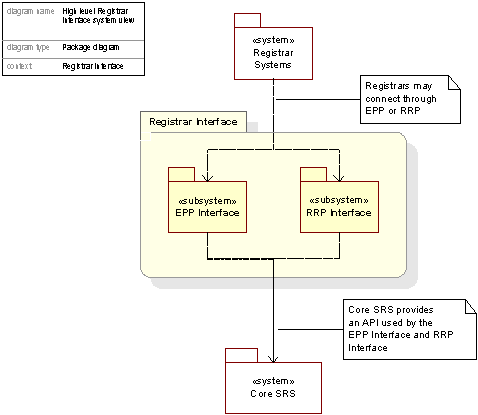
Figure 22: Decomposition of the Registrar Interface package, system view
The Registrar Interface provides the necessary protocol dependent interfaces used by the registrars to issue domain related transactions. GNR proposes to support the Registry Registrar Protocol (RRP) (currently supported by VeriSign for .org) and the Extensible Provisioning Protocol (EPP) (currently supported by Global Name Registry for .name), as described in Sections C17.2 and C22. Future protocols may be added upon need. The Registrar Interface’s main responsibility is to maintain and administrate registrar connection sessions (connection handling, authentication, etc.), validate command syntax, and translate the protocol specific commands to the protocol independent Core SRS API provided by the Core SRS.
Reliability and security
Thanks to load balancing and failover systems, the reliability of the Registrar interface is extremely high. Security is ensured through GNR’s extensive use of state-of-the art firewalls, Intrusion detection systems, custom hardened software and in-house developed API interfaces. For more information about reliability and security, please see Section C17.9, C17.10 and C17.13.
Scalability
The EPP/RRP access point scales linearly due to the load balancing on the front end towards the Registrar. Thanks to centralized storage (these servers are diskless) there is no practical limit to the number of EPP/RRP servers that can be added to the system to provide more connections and processing capacity of the protocols supported. Further, all protocol specific processing and logic is residing on these frontends.
For more information on this scalability, please consult Sections C17.3, C17.10, and C22.
2.1.1 Mapping components to hardware – Deployment view of the Registrar Interface package
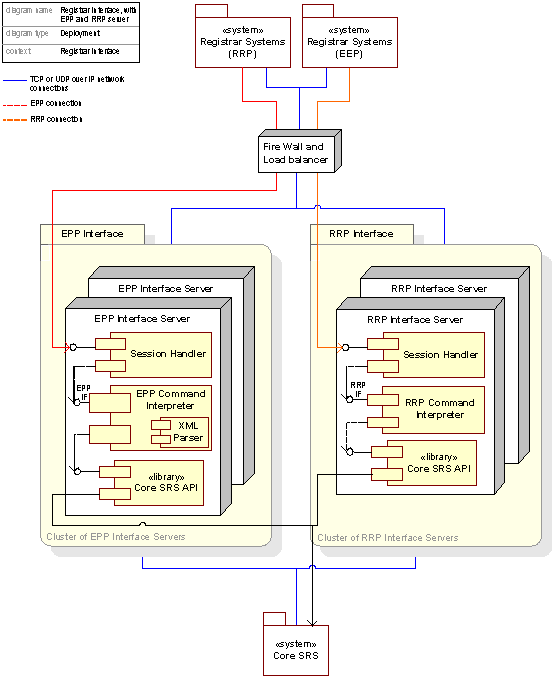
Figure 23: The Registrar Interface, deployment view
The EPP and RRP interfaces are deployed on a set of clustered front end servers accessible through a firewall and load balancer. A cluster approach enables easy scalability through addition of additional servers when needed.
See Section C17.2 for a detailed description of the RRP and EPP implementations.
Hardware specifications for the Registrar Interface system deployment
|
Registrar Interface hardware specifications |
|
|
EPP Interface Server |
IBM X350 Xeon 700Mhz processors, 2.5Gb memory, 10.8Gb disk space, x3 in UK, x3 in NO |
|
RRP Interface Server |
IBM X350 Xeon 700Mhz processors, 2.5Gb memory, 10.8Gb disk space, x3 in UK, x3 in NO |
2.1.2 Control flow – process view of the Registrar Interface package
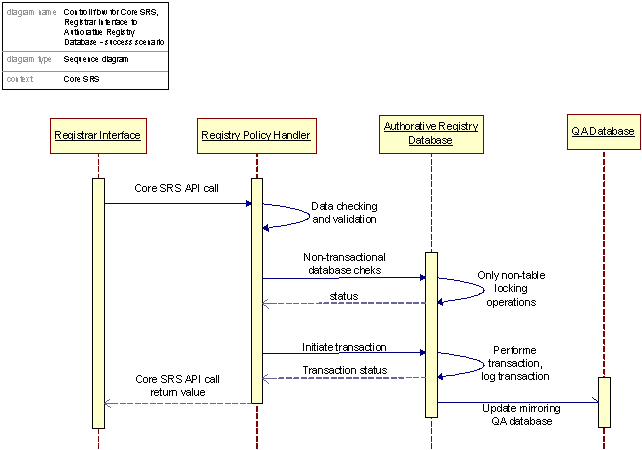
Figure 24: Control flow for the Registrar Interface, transaction request.
2.2 Core SRS
The Core SRS package represents the heart of the registry, containing the authoritative database containing all domain, nameserver, contact, registrar account information, etc.
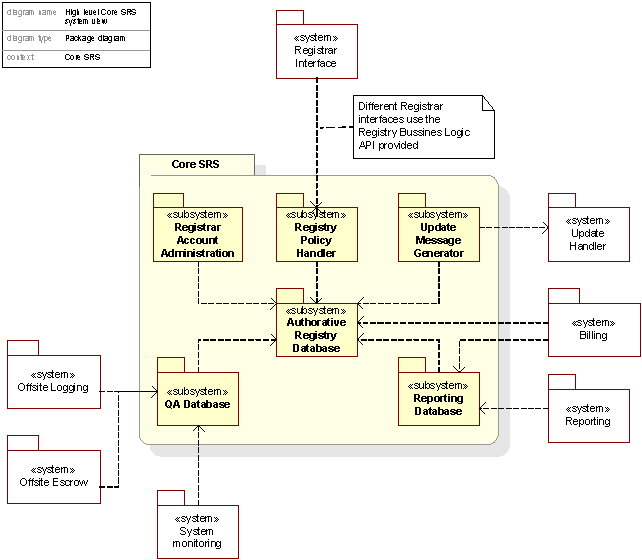
Figure 25: Decomposition of the Core SRS package, system view
The Core SRS package consists of the following subsystems:
The Registry Policy Handler implements the business logic layer. This subsystem also provides the Core SRS API used by the Registrar Interface. This subsystem is actually implemented as a thin layer consisting of a class library compiled into a dynamic linked library accessible to presentation layer components (e.g. EPP Interface and RRP interface).
The Registrar Account Administration system, providing functionality for administrating Registrar account information stored in the Authorative Registry Database.
The Authoritative Registry Database consists of the registry’s main database. The database is designed to support a thick registry, meaning a registry also holds contact information associated with domains. Most of the business logic in Core SRS is implemented through stored procedures in the Authoritative Registry Database.
The Reporting Database contains information used by the Reporting and Billing systems. It is a modified subset of the information stored in the Authoritative Registry Database.
The Quality Assurance (QA) Database is a read-only mirror of the Authoritative Registry Database. Its main purpose is to reduce the load on the Authoritative Registry Database for operations that don’t require write access to the database. Its primary client is the Automatic Consistency Validation system, which makes extensive use of the QA Database.
The Update Message Generator represents the linkage between the Core SRS system containing authoritative data, and the Resolving Service systems that provide the public interfaces to this information. The Update Message Generator is responsible for the propagation of changes made in the Authoritative Registry Database to the systems responsible for updating the public services (Whois and DNS).
Reliability and security
The core SRS system is spread on three databases running on Oracle on IBM AIX, and the business logic layer runs on a load balanced server set that can be linearly scaled. The security of the authorative database is extremely high and ensured due to the use of state-of-the art, proven software, custom applications and skilled operators. For more information, please consult Sections C17.9, C17.10 and C17.13.
Scalability
The Registry Policy Handler contains all the non-protocol specific rules and processes. Its job is to translate the non-protocol specific commands into appropriate database commands according to the database structure and business rules. The Registry Policy Handler scales linearly and more Registry Policy Handlers can be added just like EPP servers, since the Policy Handler does not lock any particular information internally for the transactions. GNR has the option of implementing a load-balancing policy into the EPP servers, which would allow them to use a layer of multiple Registry Policy Handlers. To further help scalability, the Policy Handler does a significant amount of consistency checking and rules checking involving read commands in the database, which offloads the database and allows for more processing to be done in a linearly scalable layer
For more information on the business rules this layer processes, and the databases, please consult Section C17.3 and C22.
2.2.1 Mapping components to hardware – Deployment view of the Core SRS
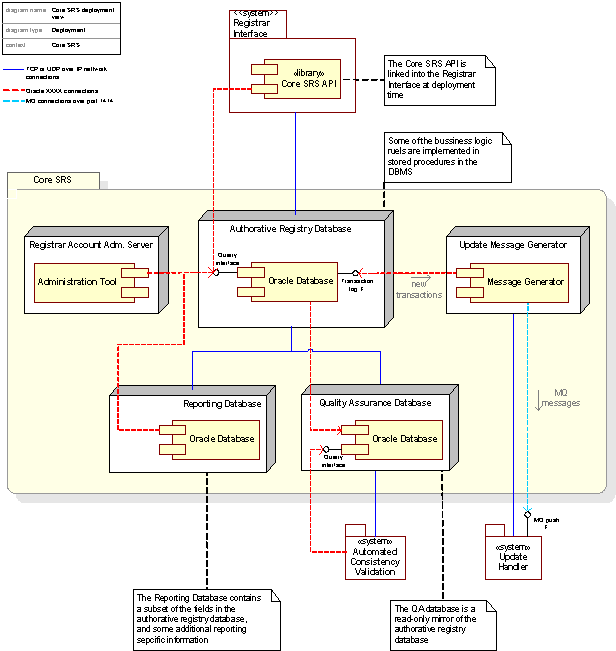
Figure 26: The Core SRS, deployment view
In the current design of the system the business logic layer has been split into a linked library providing the Core SRS API and a set of stored procedures in the Authoritative Registry Database accessed by the previous mentioned library. Due to this design there is no dedicated application server or cluster of servers responsible for implementing what would be the business layer in a distributed system. One might, when necessary, move business logic related functionality out of the Authoritative Registry Database system and into a specialized application server environment.
Hardware specifications for the Core SRS system deployment
|
Authoritative Database Server |
IBM RS6000, running Oracle 8.1 on AIX |
|
QU Database Server |
IBM RS6000, running Oracle 8.1 on AIX |
|
Reporting Database Server |
IBM RS6000, running Oracle 8.1 on AIX |
|
Registrar Account Admin. Server |
IBM X330, 2X Pentium 1000mhz processors, 2.0Gb memory, 16.8Gb disk space |
|
Update Message Generator |
IBM X330, 2X Pentium 1000mhz processors, 2.0Gb memory, 16.8Gb disk space |
2.2.2 Control flow – process view of the Core SRS package
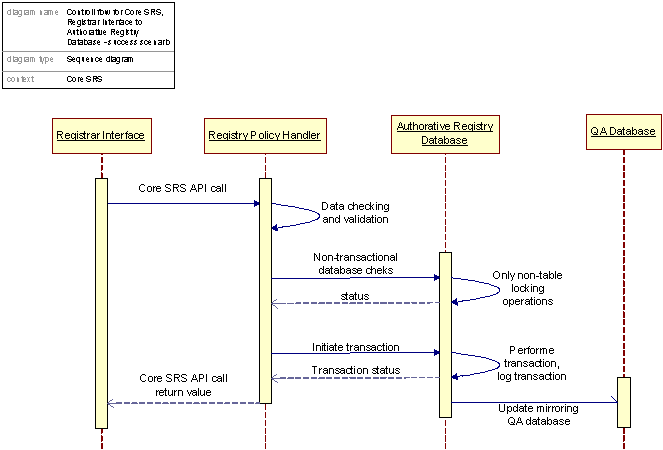
Figure 27: Control flow for the update of Core SRS
The control flow inside the Core SRS system as illustrated for a registrar initiated request is relatively straight forward. An overall design focus has been to minimize the number of necessary table locks caused by transactions spanning multiple database operations or fragmented write operations, thereby maximizing the through put of the database. This is accomplished, among other things, through an early detection strategy, meaning that database dependent checks that can be performed without transactional requirements are run before the actual database transaction is necessary to execute the command. If any of these pre-transaction checks fail, command execution is stopped and a appropriate result code is returned.
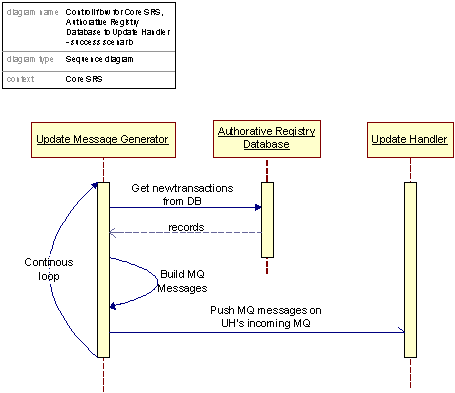
Figure 28: Control flow Core SRS Update, Update process
The Update Message Generator sole mission is to get new, committed transactions from the Authoritative Registry Database, build MQ Messages, and push them onto the Update Handlers queue for incoming messages.
2.2.3 The MQ message format
The messages (MQ messages) sent on the different MQ’s throughout the system all conform to a predefined textual format: Each MQ message consists of four basic parts:
· A header part, containing the following fields:
· transid: which is a unique transaction ID, guarantied to be in incremental order.
· MessageID: consisting of a timestamp (message creation time) and number, together creating a unique ID.
· MessageType: text string indicating type of message.
· An audit trail part, containing a XML document with nodes for each processing step the message has been through.
· A payload part, containing the actual command message. This part will be called the update message.
· Error MQ messages also consists of the full MIME encoded original MQ message that the MQ Error message is related to.
The following figure shows an example of an Add Domain MQ Message:

Figure 29: The MQ Message format
2.3 Update Handler
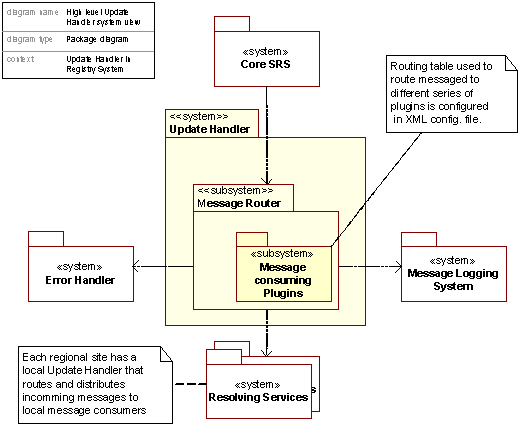
Figure 30: Decomposition of the Update Handler package, system view
The Update Handler is one of the central systems regarding real time update of the resolving services. It is designed to solve the problems of congestion due to massive update requests and the distribution of update messages to its appropriate receivers in a cost (resource) effective, reliable and highly scalable way.
To achieve this, a highly configurable message routing component has been built. This Message Router basically has the ability to take a message, look up its destinations in a routing table, and forward the message (or copies of the message if there are more than one destination) to its destination(s). The system is plug-in based, meaning that the rules governing the message sources and message destinations can be easily changed and scaled. The system currently only makes use of one plugin, a MQ-plugin enabling the Message Router to talk to MQ queues.
The routing table, which holds a matrix linking update message types to message destination, is runtime configurable through the reloading of a XML configuration file.
Reliability and security
Reliability, security and congestion issues are primarily handled by functionality provided by the MQ Message system, described in more detail in Section C17.9.
Scalability
Scalability is provided through the possibility of setting up several distributed Update Handlers in a tree-like structure. This way messages destined for a cluster of message-consumers are routed to a separate Update Handler dedicated to routing and distributing messages among the consumers inside this cluster. This is already the case for routing and distribution of messages to regional sites like the GNR Disaster Recovery Site. Each regional site has its own Update Handler (a Local Update Handler) responsible for the site-internal routing and distribution of messages. This design allows update processes and volumes to easily scale to accommodate larger volumes.
Local Update Handlers
The local Update Handlers have the same functionality as the main Update Handler, i.e. the same software, same services etc., but with different routing configuration files depending on what resolving services are located at the site in question.
2.3.1 Mapping components to hardware – Deployment view of Update Handler package
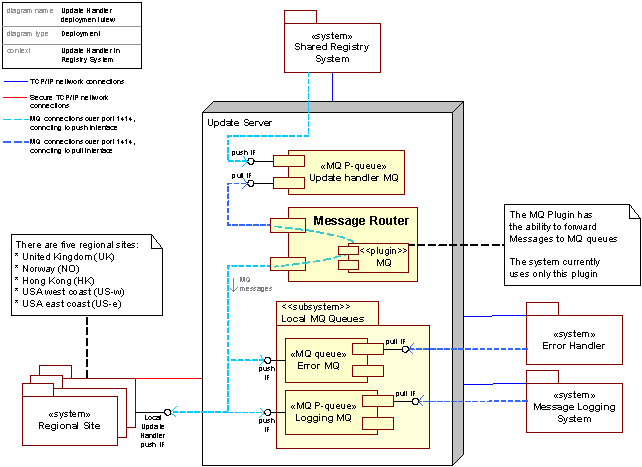
Figure 31: The Update Handler, deployment view
The current deployment makes extensive use of MQ queues. All routing sources and destinations are currently MQ queues accessed through the MQ plugin. On the main Update Handler the following local queues are run:
|
Main Update Handler MQ queues |
||
|
Queue name |
Description |
Public available interface |
|
Update Handler MQ |
All MQ Messages to be routed by the Message Router are put on this queue. This queue is persistent, meaning it guarantees delivery of received messages even after a system crash. |
Push |
|
Error MQ |
MQ Messages that at some processing step are found to be invalid or corrupted are pushed on this queue. The Error Handler system pulls MQ messages of this queue. |
Pull |
|
Logging MQ |
All MQ messages sent to the Update Handler are copied to this queue. The Message Logging system pulls MQ messages of this queue. This queue is persistent, meaning it guarantees delivery of received messages even after system crash. |
pull |
In addition, the main Update Handler pushes MQ messages on the Update Handler MQ of local Update Handlers located at the regional sites.
Hardware specifications for the Update Handler system deployment
|
Update Server |
IBM X330, 2X Pentium 1000mhz processors, 2.0Gb memory, 16.8Gb disk space |
2.3.2 Control flow – process view of the Update Handler package
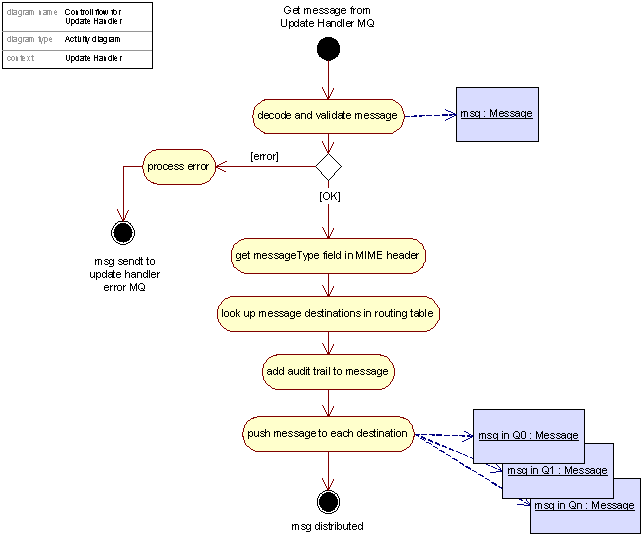
Figure 32: Control flow for the Update Handler
The process of routing a MQ Message is relatively straight forward. Messages are pulled out of the Update Handler MQ and based on the value of the MIME header field named Message Type (see Figure 29); the message is forwarded to its destinations as specified in message routing table. In addition a new audit trail node is inserted into the audit trail part of the message, denoting that the message has been processed by the Update Handler.
As mentioned before, the actual delivery of the message to its destinations is handled by destination media specific plug-ins implementing the necessary interfaces needed for communicating with the media in question. The same goes for retrieval of messages from its source. Currently only one communication medium is supported, namely MQ queues, made accessible through the MQ plug-in as illustrated in Figure 31.
In the case of unexpected process termination, full loss-less recovery is provided through the use of persistent queues at the input side of the Message Router (the Update Handler MQ) as well as at the logging end of the Message Router (the Logging MQ). A Message pulled from the Update Handler MQ is not removed from this queue before it has successfully been forwarded to all its destinations, guaranteeing that messages lost in transit due to system failure will be re-processed when proper system operation has been reestablished. This also goes for the Error MQ, guaranteeing that complete history of processed messages is maintained.
2.4 The DNS system
The DNS system is one of two systems making up the Resolving Services. It is the endpoint of any MQ messages that affects the information residing in the zone files on which the DNS resolving servers depend. The DNS resolving service is a crucial and critical part of the systems operated by the Registry. Its stability, capacity and, not the least, consistency with information in the Core Registry Database is of utmost importance for the stability of the .org segment of the Internet. With this in mind, the DNS service has been design to achieve the highest level of security, accessibility, scalability and reliability.
Since changes made to the Authoritative Registry Database are reflected in the DNS System almost instantaneously, there is no clear border between what can be called the zone file generation process and the zone file distribution process. Traditional Registry System designs have often made this distinction, denoting a conceptual separation of concern among system components. According to this paradigm there would typically be a component responsible for the periodical generation of a complete zone file based on information in an authoritative database, and another component responsible for the distribution of this master zone file to all processes depending on this master zone file, e.g. the DNS servers.
Due to this lack of a clear border between zone file generation and the zone file distribution we will in the following describe the DNS System as one, integrated whole. Section C17.4 – Zone File Generation and Section C17.5 – Zone File Distribution And Publication will present a detailed view of the DNS System focusing on respectively zone file generation and zone file distribution. There will be some overlap between this section and the chapters C17.4 and C17.5, but we advise the reader to read these two chapters after having read this section.
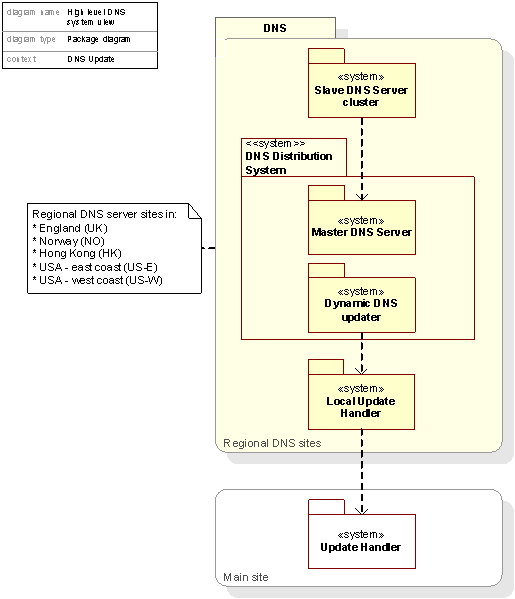
Figure 33: Decomposition of DNS Update, system view
The DNS subsystems
At each regional site (see Subsection 1.2.4 Geographical distribution of Registry Systems) there are a number of local services realizing the DNS distribution system and resolving service:
The Local Update Handler is responsible for distributing MQ Messages received from the Update Handler at the main site. The Local Update Handler is shared among all the MQ Message consuming systems inside a regional site.
The Dynamic DNS Updater is responsible for updating the Master DNS Server. Its prime task is to pull MQ Messages of the Local Update Handlers DNS queue, convert those messages into DNS update messages and send them to the Master DNS Server. The zone file update process is described in further detail in Figure 35: Control flow for DNS Update process.
The Master DNS Server is responsible for the propagation of updates in its local zone file to the local cluster of Slave DNS Servers. The Master DNS Server acts as a stealth primary DNS server, not public accessible but authorative for the cluster of public accessible Slave DNS Servers. The Master DNS Server to Slave DNS Servers update process is described in further detail in Figure 36: Control flow for DNS Update process, Master DNS Server.
The Slave DNS Server Cluster provides the actual public available DNS resolving service.
Unique to the design presented in this application is the concept of real-time, or near real-time, update of information publicly available through the Resolving Services, hereunder the Domain Name Service (DNS). To achieve this in a reliable and secure way we have designed systems that A) provide efficient means of distributing and transporting update messages to these services, and B) secure the correctness of the information made accessible through these same services.
A – Achieving reliable and efficient updates of DNS information
Functionality for transporting update messages from the Core SRS to the DNS system is provided by the Update Handler (described in the preceding Subsection 2.3 – Update Handler) through the use of message queuing software. The use of queuing technology is an efficient means of handling situations of excessive update message influx that would other ways cause congestion by allowing the frequency of messages arriving at the incoming end of the queue to be substantial higher than that of the outgoing side for a period of time. In practice this means that as long as the rate of messages being pushed from the Update Handler onto the DNS Update Queue is lower or equal to the rate that the DNS Dynamic Update Server is capable of processing messages, the changes caused by a Registrar initiated transaction will be reflected in the DNS Master Server almost instantaneously.
B – Securing the correctness of DNS information
The communication between the Core SRS system and the DNS system is mainly asynchronous, so putting the end to end update process under the supervision of some transaction system would potentially degrade system performance severely. Therefore, there has to be some mechanism ensuring that situations where information about updates somehow is lost or corrupted on its way from the Authoritative Registry Database to the DNS Servers is detected and corrected. A situation of lost update information (in most cases – lost or corrupted MQ Message) can arise due to hardware or network failures etc., and the possibility of such things happening can never be totally ruled out. A dedicated system (the Automated Consistency Validation System) has been designed for handling these issues.
What the Automated Consistency Validation System does, is for each transactions affecting the content of the Resolving services, in this case the DNS Distribution Service, to compare the authoritative information stored in the QA Database with information stored in the Resolving Service. If there is not an absolute consistency across these information sources, action will be taken automatically to correct the discrepancy. More on this in chapter 2.6 - The Automated Consistency Validation System.
Reliability and security
Some of the issues concerning security and reliability have already been touched upon in the previous section. Issues regarding the transportation of MQ Messages from the Core SRS to the DNS system are handled by the Update Handlers. Updates of the Master DNS Server and Slave DNS Servers are handled by standard Bind9 functionality.
GNR currently uses BIND9 for .name operations and has thoroughly tested and analyzed its design, update mechanisms and functionality.
The DNS Slave Server Cluster is located behind a firewall and load balancer assuring even load on servers in the cluster. Communication between Update Handler at main site and the Local Update Handler runs over a secure Internet connection.
Scalability
The main means of achieving scalability is through expanding the DNS Slave server cluster. The highly configurable routing and distribution mechanism provided by the Update Handler also makes it relatively easy to set up additional regional sites (at least from a message distribution point of view).
2.4.1 Mapping components to hardware – Deployment view of the DNS package
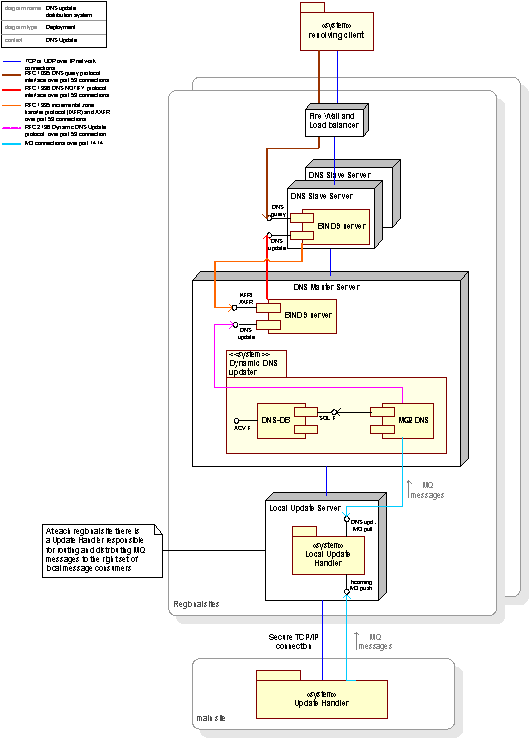
Figure 34: The DNS Update, deployment view
The main components deployed on the different servers constituting the DNS system are:
The MQ2DNS component that provides functionality for pulling MQ Messages off the DNS queue on the Local Update Handler and after a series of processing steps, as described in Figure 35: Control flow for DNS Update process, send a DNS update message to the master Bind server. The MQ2DNS component is the main component of the Dynamic DNS Updater.
The DNS-DB component, providing functionality for storing MQ Messages. The DNS-DB component is used by the MQ2DNS component for storing MQ Messages. This is to keep track of messages that cannot be sent to the Bind Master component due to unresolved update message dependencies. The DNS-DB component also provides an interface used by the ACV system for retrieval of messages (called service objects in subsection 2.6 The Automated Consistency Validation System)
The Bind 9 component is used in both the Master DNS server and in the Slave DNS servers. It contains functionality for providing the actual resolving service, as well as master – server update mechanisms.
Hardware specifications for the DNS system deployment
|
DNS hardware specifications |
|
|
DNS Slave Servers |
IBM X350 Xeon 700Mhz processors, 2.5Gb memory, 10.8Gb disk space x16 in US, x4 in UK, x4 in NO, x4 in HK |
|
DNS Master Server |
IBM X350 Xeon 700Mhz processors, 2.5Gb memory, 10.8Gb disk space, one at each site |
|
Local Update Handler |
IBM X330, 2X Pentium 1000mhz processors, 2.0Gb memory, 16.8Gb disk space |
2.4.2 Control flow – process view of DNS Update
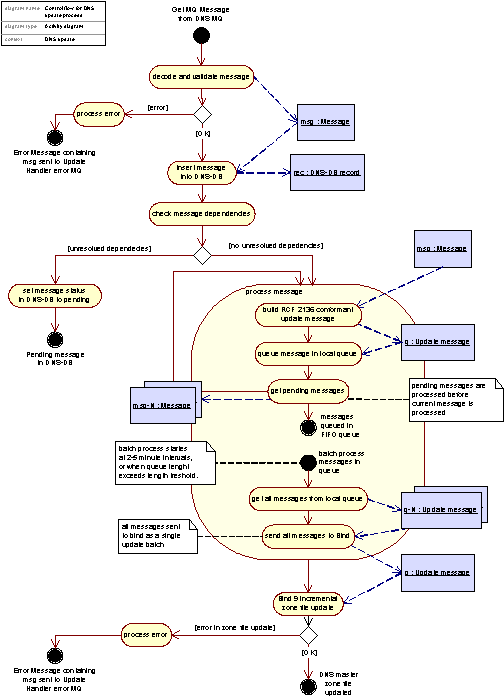
Figure 35: Control flow for DNS Update process, Local Update Handler to Master DNS Server
The process of updating the Master DNS Serves’ zone file as illustrated in the figure above consists of basically four steps (for more information on the zone file generation aspects see chapter C17.4):
Pull MQ Message off the DNS queue at the Local Update Handler, decode and validate it. If the MQ message is somehow found to be invalid or corrupt, a new MQ Error Message is created containing a description of the error in its payload (see Subsection 2.2.3 - The MQ message format), and a fourth part consisting of the full MIME encoded original MQ Message that the MQ Error Message is related to.
Check for message dependencies. Given the asynchronous characteristics of the updates, messages may arrive at different times to the recipients. Therefore, GNR has a mechanism handling messages that are related, but arriving in some disorder. An example of a disorder would be the processing of a name server (ns) add command before the domain the name server that is to be associated with it has been added. In such cases of unresolved dependencies the message being processed is put on hold (pending) until the message(s) on which the pending message is dependent on are processed. Thus messages having unresolved dependencies are stored temporarily in the DNS-DB.
Build DNS Update message. The original MQ Message has to be transformed into a valid, RFC 2136 compliant update message ready to be sent to the Master DNS Server. To avoid unnecessary communication overhead due to large number of small DNS Update messages, update messages are put onto a local FIFO message queue, enabling batched updates through sending multiple updates in one larger message. After having pushed the new update message on the queue, pending messages released by this message are removed from the DNS-DB and processed.
Send update messages to Master DNS Server. At predefined intervals the message queue will be emptied an all update messages sent to the Master DNS Server.
At this point the Master DNS Server is updated, but changes still have to be propagated to the Slave DNS Servers which provide the actual public available resolving service. The process of updating the Slave DNS Servers can be visualized as in the figure below:
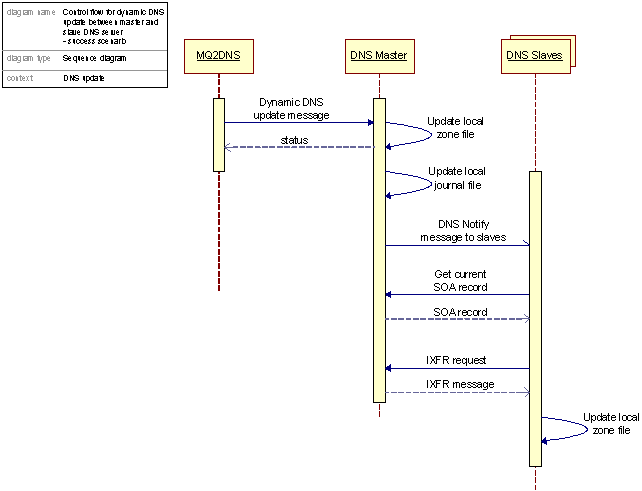
Figure 36: Control flow for DNS Update process, Master DNS Server to Slave DNS Servers
The process of updating the Slave DNS Servers consists of basically two steps (for more information on the zone file distribution aspects see chapter C17.5):
The Master DNS Server sends a DNS Notify message to each of the Slave DNS Servers notifying them of changed master zone file
The Slave DNS Servers in turn request the information necessary to bring them selves up to date from the Master DNS Server. When this information is received local zone files are updated and sync is reestablished.
A more detailed description of the process associated with what could be called the zone file generation and the zone file distribution and publication process can be found in chapters C17.4 and C17.5, we urge the reader to take a quick look at these chapters for further information concerning the DNS System.
2.5 The Whoissystem
Currently, there are Whois servers in Norway and UK but more servers can easily be added to fulfill the service volume. The Whois servers are updated separately, but simultaneously; the Update Handler provides an MQ interface to each of the Whois servers, and an update process runs on the Whois server.
A Whois update can only be accomplished as a result of a transaction in the SRS. Thus, updates are only feasible through the Registry-Registrar Interface. The updates of the regional Whois servers, including the Disaster Recovery site Whois server, will be done through a secure communication channel.
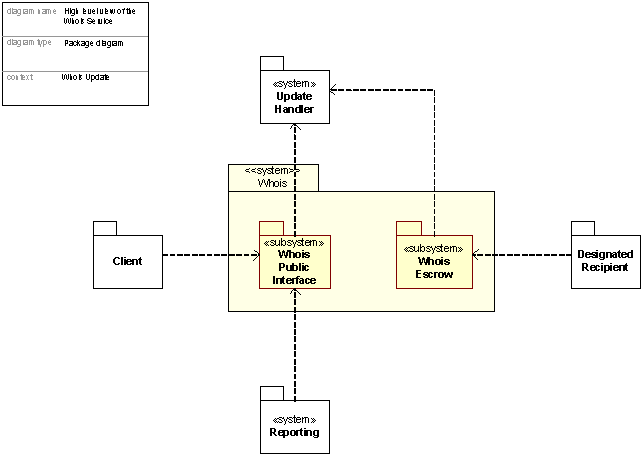
Figure 37: Decomposition of the Whois service, system view
The figure above shows an overview of the Whois service and the systems of which the service is constituted. The Whois Public Interface has a Whois database consisting all Whois entries and offers a public interface to the Whois database for look-ups through a port 43 interface accessible via UNIX commands like fwhois, and a web-interface.
In addition, the Whois System generates an Escrow file for the purpose of Appendix P (“Whois provider Data Specification”) to the Registry Contract. The Whois Escrow does not offer any public service. The Whois Escrow is a server generating XML files of the Whois database and makes them available for escrow.
Designated Recipient: GNR provides bulk access to up-to-date data concerning Registered Names, nameservers, contacts and registrars maintained by GNR in connection with the .org TLD on a daily schedule, only for purposes of providing free public query-based access to up-to-date data concerning these registrations in multiple TLDs, to a party designated from time to time in writing by ICANN
GNR has developed a custom database for the operations of Whois. The database developed is optimized for the type of requests served by Whois and greatly improves the Whois single-server performance compared to other designs. More details on the performance of the GNR Whois database can be found in Section C17.10.
The further description of the Whois package is split up in the Update process and the Public accessible look-up. The subsequent sections are focusing on the update process of the Whois servers, illustrated by a deployment and control flow diagram. For the public accessible look-up process, please see Section C17.8.
Unique to the design presented in this application is the concept of real-time, or near real-time, update of information publicly available through the Resolving Services, hereunder the Whois service. To achieve this in a reliable and secure way we have designed systems that A) provide efficient means of distributing and transporting update messages to these services, and B) secure the correctness of the information made accessible through these same services.
A – Achieving reliable and efficient update of Whois information
Functionality for transporting update messages from the Core SRS to the Whois system is provided by the Update Handler (described in the preceding Subsection 2.3 – Update Handler) through the use of message queuing software. The use of queuing technology is an efficient means of handling situations of excessive update message influx that would other ways cause congestion by allowing the frequency of messages arriving at the incoming end of the queue to be substantial higher than that of the outgoing side for a period of time. In practice this means that as long as the rate of messages being pushed from the Update Handler onto the Whois Update Queue is lower or equal to the rate that the Whois Servers is capable of processing messages, the changes caused by a Registrar initiated transaction will be reflected in the Whois Servers almost instantaneously.
B – Securing the correctness of Whois information
The communication between the Core SRS system and the Whois system is mainly asynchronous, so putting the end to end update process under the supervision of some transaction system would potentially degrade system performance severely. Therefore, there has to be some mechanism ensuring that where information about updates are somehow lost or corrupted on their way from the Authoritative Registry Database to the Whois Servers are detected and corrected. A situation of lost update information (in most cases – lost or corrupted MQ Message) can arise due to hardware or network failures etc., and the possibility of such things happening can never be totally ruled out. A dedicated system (the Automated Consistency Validation System) has been designed for handling these issues.
What the Automated Consistency Validation System does, is for each transactions affecting the content of the Resolving services, in this case the Whois Service, to compare the authoritative information stored in the QA Database with information stored in the Resolving Service. If there is not an absolute consistency across these information sources, action will be taken automatically to correct the discrepancy. More on this in chapter 2.6 - The Automated Consistency Validation System.
Reliability and security
Some of the issues concerning security and reliability have already been touched upon in the previous sections. Issues regarding the transportation of MQ Messages from the Core SRS to the Whois system are handled by the Update Handlers. The Whois Server Cluster (in the Whois Public Interface) is located behind a firewall and load balancer assuring even load on servers in the cluster. Communication between Update Handler at main site and the Whois Servers runs over a secure Internet connection.
Scalability
The main means of achieving scalability is through expanding the Whois server cluster. The highly configurable routing and distribution mechanism provided by the Update Handler also makes it relatively easy to set up additional regional sites (at least from a message distribution point of view).
2.5.1 Mapping components to hardware – Deployment view of Whois
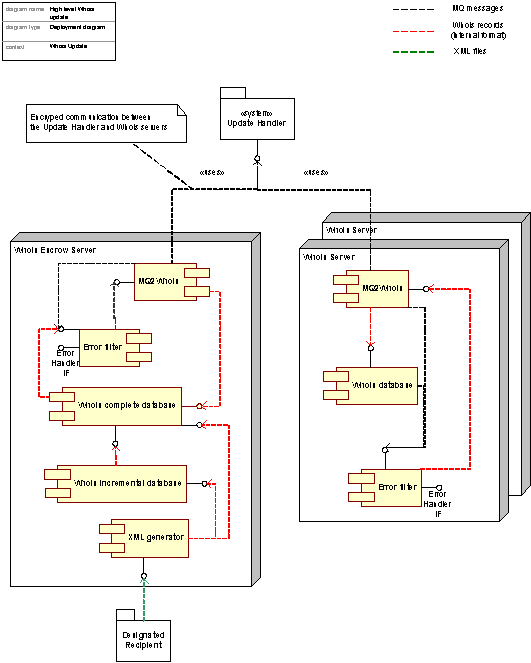
Figure 38: Whois Update and escrow, deployment view
The deployment of components operating at a Whois update is shown in the figure above. The update message is queued at the Whois MQ’s (one for each Whois servers) in the Update handler, and the MQ message is pulled from the Whois servers, i.e. the update process is done simultaneously in the Whois Public Interface and the Whois Escrow.
The Whois Public Interface Update
All Whois Public Interfaces are updated simultaneously. The MQ messages are translated to the internal Whois records and stored in the Whois Database.
Concerning possible reordered arrival of messages; update messages are identified by their transaction ID, and the message with highest transaction ID will always be stored in the database. Any messages arriving with lower ID’s will be discarded. In this way, the Whois database will always contain the most recent updates.
Any messages are checked (syntactical and semantic) for errors, and errors are detected before further processing, and handled by an Error Filter. The Whois Public Interface logs all updates internally.
The Whois Escrow Update
The Whois Escrow receives all Whois update messages. The MQ messages are transformed into a internal Whois format and stored in the Whois Complete Database. The Whois Complete Database will be identical to the Whois Database in the Whois Public Interface, but to in order to ease the load of the Whois Public Interfaces, the Whois Escrow is dedicated for the escrow service. The Whois Incremental Database then polls records from the complete database.
The XML generator prepares XML documents and are stored in a file named according to Appendix P (“Whois provider Data Specification”) to the Registry Contract for a designated recipient, either incremental data set or full data set depending on date/time. The transmission of the datasets is handled according to the same appendix.
The Error Filter is identical to the Error Filter in Whois Public Interface.
Hardware specifications for the Whois system deployment
|
Whois hardware specifications |
|
|
Whois Server |
IBM X330, 2X Pentium 1000mhz processors, 2.0Gb memory, 16.8Gb disk space, x2 in UK, x2 in NO |
|
Whois Escrow Server |
IBM X330, 2X Pentium 1000mhz processors, 2.0Gb memory, 16.8Gb disk space |
2.5.2 Control flow – process view of Whois
The figure below shows the update process for the Whois Public Interface, while the subsequent figure presents the additional steps for Whois Escrow.
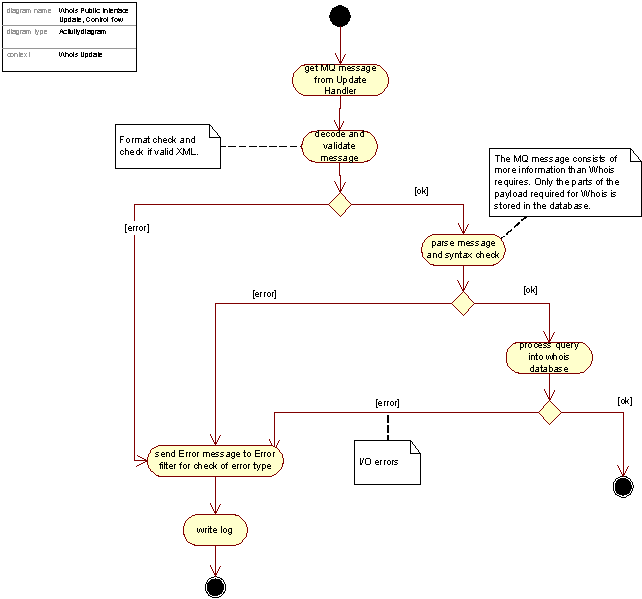
Figure 39: Control flow in the Whois Update process
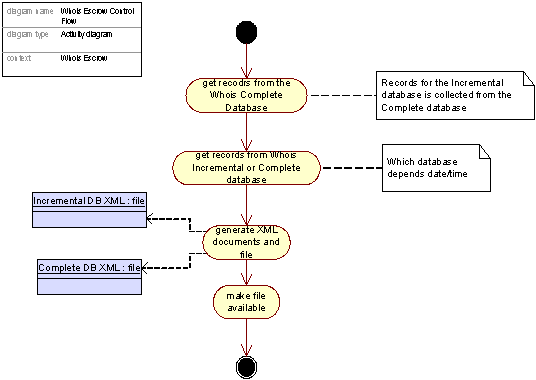
Figure 40: Control flow in the Whois escrow process
2.6 The Automated Consistency Validation System
The Automated Consistency Validation (ACV) system is a system responsible for assuring the consistency across the information held in the Core SRS and information published by the Resolving Services. The system holds a crucial role in assuring the correctness of the near real time update of the Resolving Services.
In the following description, information in
the Core SRS will be referred to in terms of transaction objects residing in the QA Database. The QA Database
is, as explained in Subsection
2.2 Core SRS, a read only mirror of the Authoritative Registry
Database. Information concerning the Resolving Services will be referred to in
terms of service objects residing in
Resolving Services, i.e. the DNS System and the Whois System.
The goal of the ACV process is to identify, log and to the extent possible, automatically correct inconsistencies occurring during the process of updating the Resolving Services from the Authoritative Registry Database.
Inconsistencies refer either or all of the following situations:
· The service objects on the Resolving Services are corrupted. This happens due to many reasons, e.g., noise interference on communication channel, code bugs, etc.
· The service objects on the Resolving Services are not up to date. This happens when the up to date transaction objects have not been pushed to the Update Handler by the Core SRS, or the Update Handler has obtained the objects but has not pushed them to those services such as DNS and Whois. This is also referred to as latency in Subsection 1.2.2.
Automatically correctmeans:
· In situation where the inconsistencies are resolvable, then a forced update message is sent to the Update Handler, so that each Resolving Service is updated accordingly.
· Otherwise, a warning message is logged for manual checking or further processing.
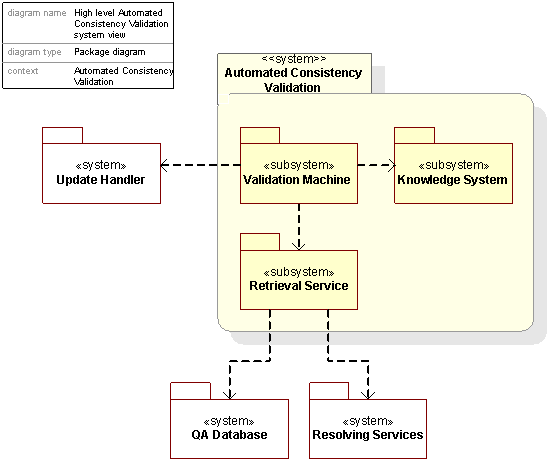
Figure 41: Decomposition of Automated Consistency Validation System, system view
The figure above illustrates the content of the ACV package and its dependent systems. Each of the identified subsystems has distinct responsibilities.
The Automated Consistency Validation subsystems
The Knowledge System:
ACV is a very resource-consuming (i.e., storage, time, memory-consuming) process. Exhaustive consistency validation will either not be possible, or heavily affect the Resolution Service’s and Core SRS performance. Therefore, a decision-making process has been introduced for making decisions about:
· What data objects should be checked;
· Which services should be checked;
· When they should be checked;
These decision-making processes are categorized into a component we call the Knowledge System. The rule set by which the Knowledge System operates is configurable at runtime, allowing the system to be adapted to changes in its operation environment. In general it can be stated that the more sophisticated data (rule sets) we have, the wiser decision the Knowledge System may make.
The Validation Machine:
The Validation Machine is responsible for the actual comparison of transactions objects and associated service objects. Which transaction objects to check is determined by the Knowledge System. According to the state a transaction object is found to be in, action is taken to correct any possible inconsistencies. The Validation Machine request service objects from the Retrieval Service as instructed by the Knowledge System. It will also in some cases recreate MQ Messages based on transaction objects and push these on the Update Handlers receiving message queue for further distribution.
The Retrieval Service:
The Retrieval Service provides functionality for retrieving service objects from the Resolving Services and transaction objects from the QA Database. Provided a set of search criteria it will request objects from the relevant Services.
2.6.1 Mapping components to hardware – Deployment view of the Automated Consistency Validation System
The ACV system environment consists of ACV server, the QA Database, The Update Handler, and the Resolving Services consisting of the DNS System and the Whois System, each of which are direct recipients of MQ Messages from the Update Handler. Indirect recipients, such as slave services of these direct recipients are not considered. The figure below illustrates the different components assembling the system as a whole.
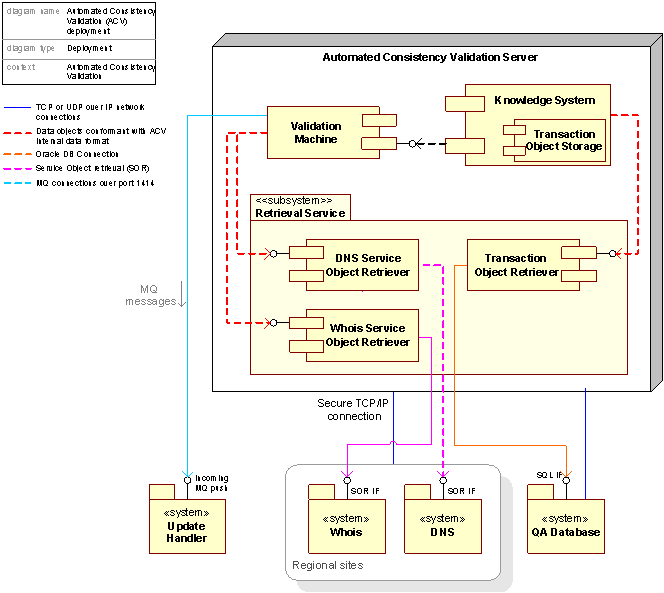
Figure 42: Deployment diagram for the Automated Consistency Validation System
The main components deployed on the ACV server are:
The Knowledge System component (KS) implements the necessary functionality for making decisions previously mentioned. The Knowledge System component makes use of an internal sub-component, the Transaction Object Storage (TOS), that provides functionality for temporarily storing transaction objects retrieved from the QA Database. The KS will pull transaction objects from the QA Database and store them in the TOS for further use. It uses the Transaction Object Retriever to retrieve transaction objects in a known format from whatever underlying database these may reside on.
The Validation Machine (VM) implements functionality for determining the state of a given transaction object. It provides an interface used by the KS for instructing the VM which transaction object to validate against what Resolving Service and what to do given the state the transaction object is found to be in. The VM uses the retrieval services provided by the DNS Service Object Retriever and the Whois Service Object Retriever to retrieve service objects in a known format from the underlying Resolving Services it is instructed to validate. The Retrieval Service is plug-in based enabling future object sources to be added through the provision of the appropriate plug-in.
The Retrieval Service, consisting of a set of object source specific plug-ins enabling the KS and VM to operate on service and transaction objects in a source independent way. Currently plug-ins for the DNS Service, the Whois Service, and the QA Database are provided. In the current design each of the Resolving Services provide a dedicated interface for retrieval of service objects. Each service is responsible for making received MQ Messages containing service objects persistent and thereby enabling later retrieval of these.
Hardware specifications for the Automated Consistency Validation system deployment
|
Automated Consistency Validation hardware specifications |
|
|
Automated Consistency Validation Server |
IBM X330, 2X Pentium 1000mhz processors, 2.0Gb memory, 16.8Gb disk space |
2.6.2 Control flow – process view of the Automated Consistency Validation
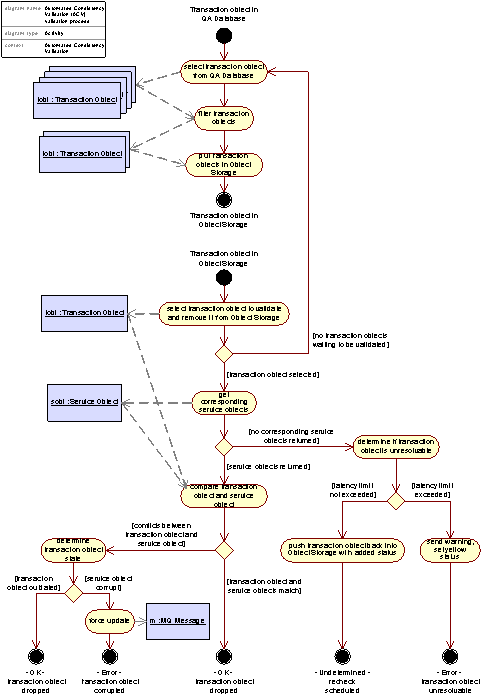
Figure 43: Control flow in the Automated Consistency Validation System
The validation process as illustrated in the figure above may briefly be described as consisting of the following step:
1. Selectively retrieve transaction objects from the QA Database. Selectively here means that not all transaction objects will be chosen for scrubbing this is mainly for reasons of efficiency. For example, transaction objects are only chosen if their update dates are within a given period.
2. Selectively retrieve service objects from selected services subset, based on transaction ids (id) and/or service ids (sid) converted from Step 1.
3. Detects conflicts between transaction objects and their correspondent service objects.
4. For each service in selected services subset, if there are conflicts, then take either or all of the following actions:
· logging the conflicts;
· send forced update message to the Update Handler
5. Go to Step 1
Terms used above are defined below:
· idis the transaction id of the main transaction table. This equals to the transid header field in the MIME header of the MQ Message. The transaction id is guaranteed to be monotonically increasing over time.
· sid is the secondary id, or handle, associated with an object. The sid equals to the value of the handle attribute of the <domain> tag. The domain tag being part of the payload of the MQ Messages
Transaction object states
The state a transaction object may be in at any time is illustrated in the figure below. In the figure, tobj denotes a transaction object, and sid denotes a service object.
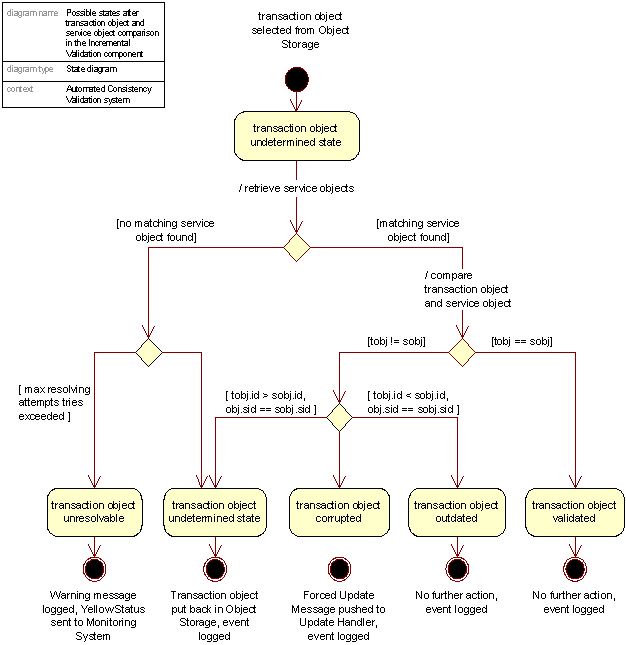
Figure 44: Transaction object state in the ACV process
A short description of the above mentioned states follows:
Transaction object unresolvable state may arise due to several circumstances.
· A forced update message has been pushed to the Update Handler, and rechecking has shown that the conflict is still there.
· The conflict is deemed as unresolvable based on the knowledge the KS has. In this case, no forced update messages will be pushed to Update Handler. For example, if a matching service object could not be found, and the maximum resolving attempts retries limit has been exceeded, the service object is assumed to having been lost or other wise corrupted to a degree making it unresolvable. The same goes for situations where history shows that there is a very big percentage of conflicts between transaction objects and the corresponding Resolving Services. Then ACV may then not try to correct these conflicts. Warning message will in this case be logged and manual checking must be made to find the cause of these errors.
Transaction object undetermined statemay arise when the KS holds insufficient information for determining the exact state of the transaction object. This may be the situation when:
· The corresponding service object was not found, but not enough information is provide to determine whether this is caused by the corruption or loss of the corresponding MQ Message, or caused by latency, i.e. the Resolving Services in question have not yet been updated, but will be in near future.
· A corresponding service object has been found, but its transaction id is smaller than that of the transaction object. This may be caused by the same phenomena as described in the previous situation.
Transaction object corrupted state is caused by the partial corruption of service object. A corresponding service object is found, but it is not identical to the transaction object, and it does not fulfil the criteria for its state being undetermined or outdated, i.e. the transaction ids of the two objects equal, but the rest of the data may differ.
Transaction object outdated state arises when a corresponding service object is found, but its transaction id is higher that that of the corresponding transaction object, meaning that a later transaction object already has overwritten the changes instructed by the transaction object mentioned above.
Transaction object validated state is reached when a corresponding service object is found, and no discrepancies between the service object and the transaction object are found.
Black holes: Corrupted service objects that can never be tested
In all discussion above, the focus is on correcting a service object that is identifiable, i.e., that can be retrieved by identities (id, or sid). However, there are objects that are not identifiable due to all identities being corrupted. They are the rubbish residing on the services which should be cleaned. The cleaning process should be treated differently, in the following way:
Periodically, all (or a segment) of the transaction objects are pulled from QA Database; they are sorted by transaction id, or sid, whichever is suitable; all (or a segment) of objects on a service or services are pulled out; they are sorted in the same way as transaction objects are; (note that service objects including unwanted objects are pulled in the range of id or sid; once objects are pulled out, then following procedures are taken:
1. For each transaction object, if there is a correspondent identifiable service object, determine its state as described previously and act according to determined transaction object state. When conflicts cannot be resolved, then warning messages are logged accordingly.
2. For each unidentifiable object, forced update messages are sent to the Update Handler to remove them; If they can not removed (after the messages are supposedly received by the due service recipients), warming message should be logged.
Whether all or a segment of objects should be checked is based on overload balance of the ACV system.
Force Update
If a service object is found to be corrupted, update message is generated with the data from the corresponding transaction object.
The force update message type is introduced to refresh data on resolution services. The force update message should contain all information normally included in an update, but additionally contain a copy of the modification time and the transaction id of the object expected to contain incorrect information.
The latter is critical in order to ensure that a force update does not overwrite updates that occur after the point in time that data integrity was verified, but before the force update message arrived at the resolution service in question.
2.7 Billing
The Billing system handles Registrars accounts in the Registry System and is trigged by billable operations (See C25-C27) initiated by a Registrar. The Registry System debits the amount of the operation from the Registrar’s Registry account. The Financial Controller, who handles billing, administers the flow of assets and invoices.
When a registration is completed, the Registrar’s account balance is debited with the price for one registration. Registrations continue as long as the balance is positive, or until a credit limit, if any, is exceeded.
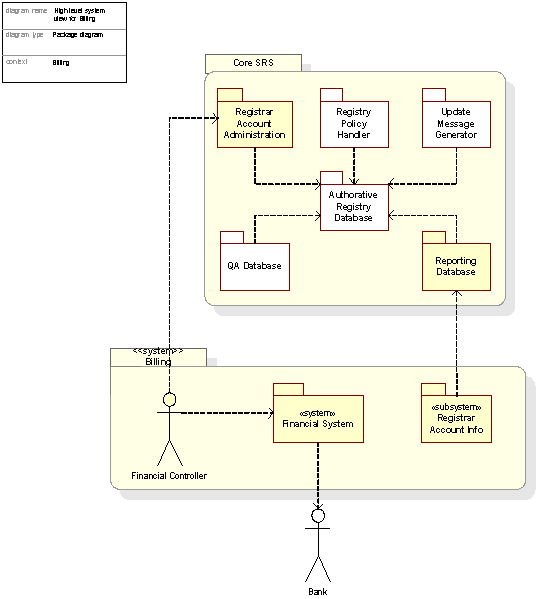
Figure 45: High-level system view for the Billing package
The figure above presents the Billing system, its subsystems and actors. These will be described in Section C17.6, along with a further description of the Billing and collection systems.
2.8 Reporting
Each month ICANN requires reports. GNR currently provides the following information in its reports:
· Accredited Registrar Status
· Service Level Agreement Performance
· TLD Zone File Access Activity
· Completed SRS/System Software Releases
· Domain Names Under Sponsorship – Per Registrar
· Nameservers Under Management - Per Registrar
· Domain Names Registered by Registry Operator
· Whois Service Activity
· Monthly Growth Trends
· Total Number of Transactions by Subcategory by Month
· Total Number of Failed Transactions by Subcategory by Month
· Daily Transaction Range
· TLD Geographical Registrations Distribution
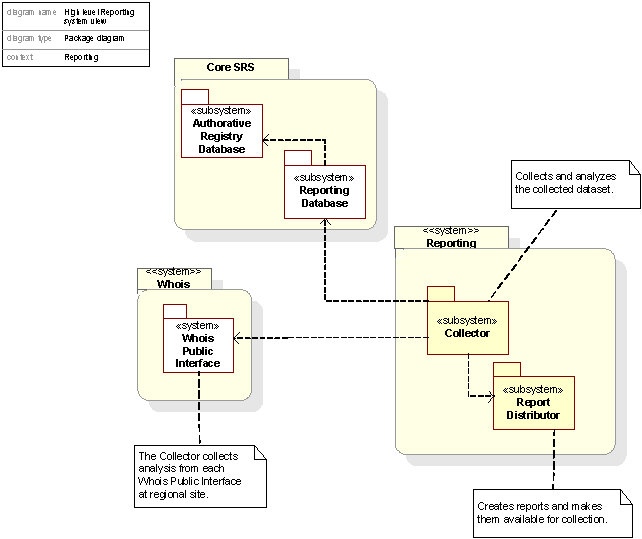
Figure 46: Decomposition of the Reporting package
The Registry System contains a reporting system handling the generation of reports. A Reporting Database in the Core SRS contains a subset of the fields in the Authoritative Registry Database, some accumulated and processed data and additional reporting specific information required to generate reports. For the Whois Service activity report, each of the Whois Public Interfaces offers an interface to the Reporting System, where analysis of each day’s service activity can be polled. The Reporting System consists of the following subsystems:
Collector: Gets datasets from the Reporting Database and the Whois Public Interfaces, makes analyses based on the requirements of the reports, and saves analysis to disk.
Report distributor: Creates reports of analyses, batches report files, and makes them available for the instances in question.
2.8.1 Mapping components to hardware – Deployment view of the Reporting package
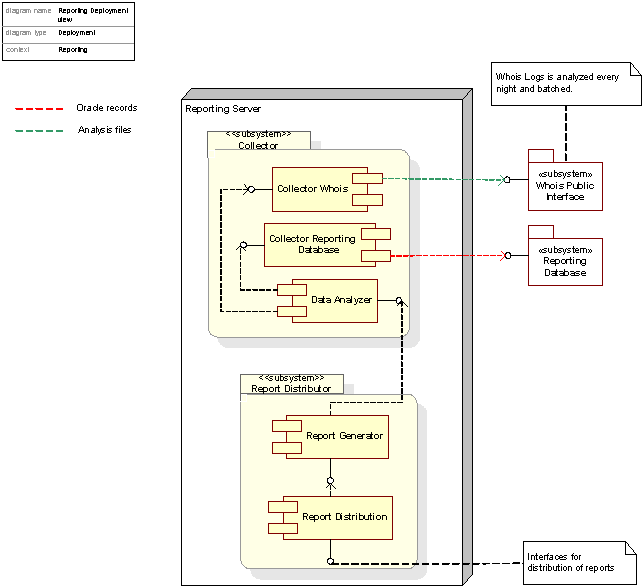
Figure 47: The Reporting system, deployment view
There are two collector components: one that collects the analysis batches from each of the Whois Public Interfaces, and one that gets report data from the Reporting Database in Core SRS. The data collected from the Reporting Database depends on the report to be generated. The Whois Public Interfaces analyzes the log of look-ups each night and makes them available for the Collector Whois component. This analysis is done monthly, or more often upon the request of the Operations Team.
The Data Analyzer makes analysis of the data from the Reporting Database, and compiles a summary analysis of all the Whois analyses. The final analyses are put on an interface for the Report Generator, which generates reports consisting of the analyses. The Report Distribution component distributes the reports by making them available for download.
Hardware specifications for the Reporting system deployment
|
Reporting system hardware specifications |
|
|
Reporting Server |
IBM X330, 2X Pentium 1000mhz processors, 2.0Gb memory, 16.8Gb disk space |
2.8.2 Control flow – process view of the Reporting package
The diagram below illustrates the control flow for a report, in this case the Whois activity report that is part of the monthly reporting to ICANN.

Figure 48: Control flow for the Reporting process
2.9 Offsite Logging
GNR logs all transactions performed in the Registry System and stores the logs offsite in Norway. To limit the load on the main database, the Quality Assurance Database, which is a continuously updated, read-only mirror of the main database, is used for the Offsite Logging purpose. The QA Database contains Oracle archive logs of all transactions; these logs are batched continuously and sent offsite. The Figure below illustrates the packages that are involved in, and constitutes the Offsite Logging system.
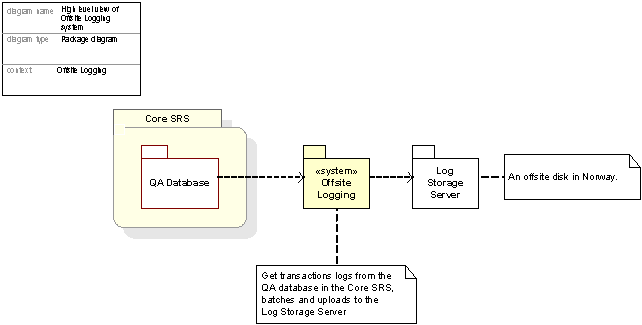
Figure 49: The Offsite Logging System and its dependent packages
The Offsite Logging system sends a log of transactions to the Disaster Recovery Site (“DRS” or “Backup site” in the diagram below) in Norway. This log ensures that the DRS is replicated from the UK main site and ready to take over operations in the case of a fail over scenario.
The diagram below provides some more detail on the offsite logging mechanism. More information about the database replication can be found in Section C17.3
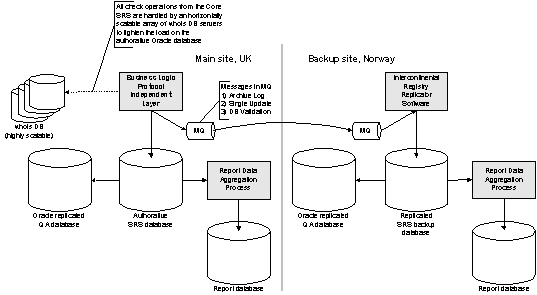
Figure 50: Replication of databases, inter-site and inter-continental
Reliability and security
The MQ link between the two remote sites is running over a VPN with strong encryption. This ensures the security of the link.
GNR has several bandwidth providers and backbones connected to the site, but should the link be down, the MQ queuing system will guarantee that all messages are queued and sent when the link comes back up.
Scalability
The log volume handling of the design is high and a very high number of changes can be replicated with this method. GNR does not foresee any problems with this method even with tens of millions of registered names.
2.9.1 Mapping components to hardware – Deployment view of the Offsite Logging package
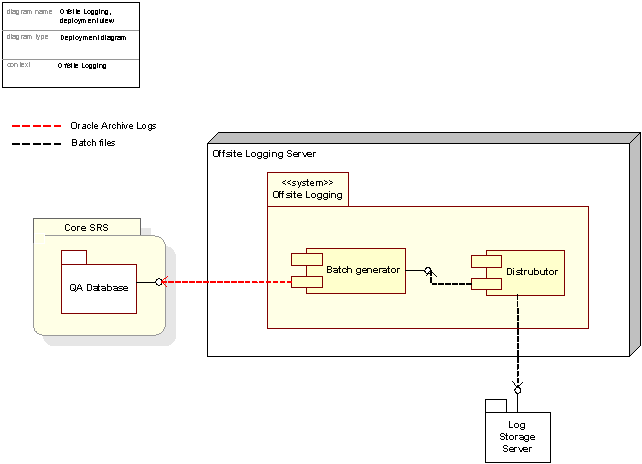
Figure 51: Offsite Logging, deployment view
Please see Section C17.3 ‘Intercontinental Registry Replication’ for more about the Offsite Logging and backup.
Hardware specifications for the Offsite Logging system deployment
|
Offsite Logging hardware specifications |
|
|
Offsite Logging Server |
IBM X330, 2X Pentium 1000mhz processors, 2.0Gb memory, 16.8Gb disk space |
2.9.2 Control flow – process view of the Offsite Logging package
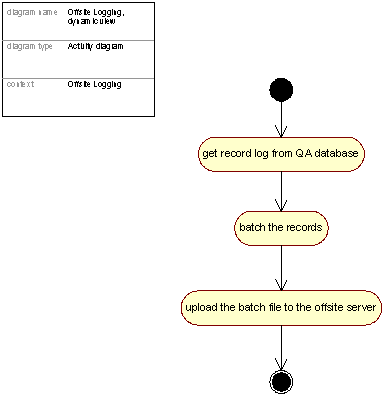
Figure 52: Control flow for Offsite Logging
2.10 Offsite Escrow
As described in Section C17.7 on Escrow, a copy of the Authorative Registry Database is sent to a secure storage place offsite on a regular basis. To limit the load on the main database, the Escrow is generated from the Quality Assurance Database, which is a continuously updated, read-only mirror of the main database. Only ICANN and/or the Registry may access these copies.
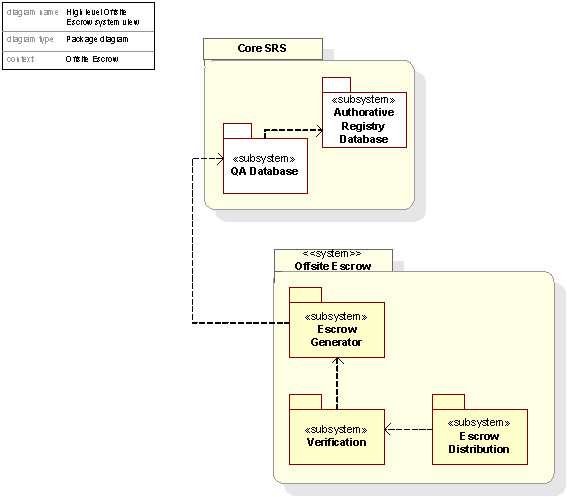
Figure 53: Decomposition of the Offsite Escrow, system view
Escrow Generator: Generating escrow (deposit) files according to the format specification, and incremental or full dataset depending on time and date.
Verification: A program provided by ICANN that verifies that the file complies with the format specification and contains reports of the same date/time (for a Full Deposit)
Escrow distribution: A system that splits the resulting file using the Unix SPLIT command (optional), and in that case include a .MD5 file to isolate errors in case of transfer fault. The system then encrypts the file with PGP, and is sent, by anonymous file transfer, e-mail, or similar which will agreed by Registry Operator and the escrow agent, starting in the specified time window.
In addition to what GNR feels is a safe and flexible backup-solution, we place additional data security by depositing data to an escrow service. This will place additional data security on the organizational level in that we actually deposit data in case a conflict occurs. The escrow function will be taken care of by an Escrow company, as described and identified in Section V17.7. GNR submits data to the escrow service on a predefined schedule. The escrow agent will ensure that data is protected and is made available to the correct owner in the event that retrieval of the escrow file should be necessary.
Data is transferred in a strongly encrypted form to the Escrow agent over the Internet, after which the Escrow Provider stores deposits in secure vaulting facilities designed to hold electronic items.
Escrow of Whois records are mentioned in Subsection 2.5 – Whois Service, and further described in Appendix P – Whois provider Data Specification. Please see Section C17.7 for further descriptions of Escrow.
Hardware specifications for the Offsite Escrow system deployment
|
Offsite Escrow hardware specifications |
|
|
Offsite Escrow Server |
IBM X330, 2X Pentium 1000mhz processors, 2.0Gb memory, 16.8Gb disk space |
2.11 System Monitoring
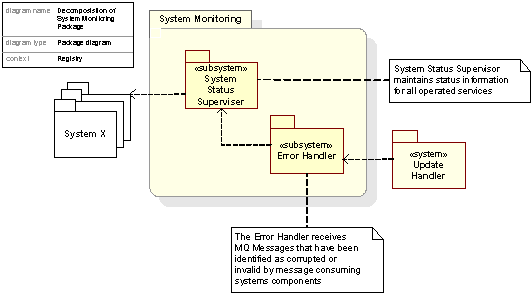
Figure 54: Decomposition of the System Monitoring package
System Status Supervisor maintains status information for all operated services. Using a combination of stand-alone and client-server systems, monitoring data is collected using both push and pull technology. Statistical analysis is performed on this data to allow more useful representation of the information and trend analysis to aid in diagnosing behavioral patterns. Operations Staff are promptly notified of any errors, problems, and suspicious or unexpected behavior on any server in any site.
All services are also monitored externally by AlertSite, Servers Alive, Big Brother and several bespoke tests. It is essential that systems not be monitored by any one system and that they are tested by several means and alternate sources. This ensures that we have a clearer picture of what is happening on a global scale with ample redundancy and no single points of failure.
The Update Handler provides a MQ Message queue for messages containing errors detected in any MQ Message consuming and processing part of the Registry System, and the Error Handler pulls messages from the Error MQ, writes an entry to a log, and warns NOC.
2.11.1 Mapping components to hardware – Deployment view of the System Status Supervisor
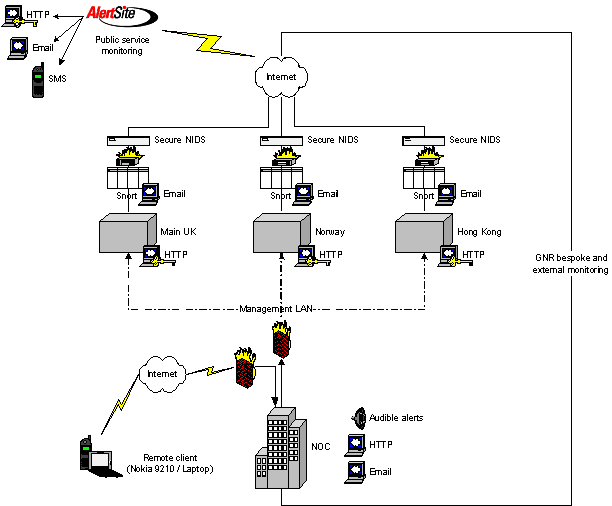
Figure 55: An overview of the System Monitoring architecture
The software and systems used by the System Status Supervisor are:
· Big Brother
· Multi Router Traffic Grapher (MRTG)
· RRD
· SNMP
· Snort
· Servers Alive
· AlertSite
See subsection below and Section C17.14 for descriptions of these systems. In addition, GNR use two different Network Intrusion Detection Systems (NIDS). These systems are Cisco Secure NIDS and the Linux based Snort, an open source NIDS. Both systems are signature based NIDS. This means that both systems access a database with well-known attack signatures and compare all traffic (incoming and outgoing) against these signatures. If a signature is found, the NIDS will issue an alert message. The alert messages are sent via e-mail to the Operations team in the NOC for further investigation. NIDS is detailed in Section C17.9.
2.11.2 Control flow – process view of the System Status Supervisor package
The figure below presents the Client/Server communication and control flow in the system status supervisor process.
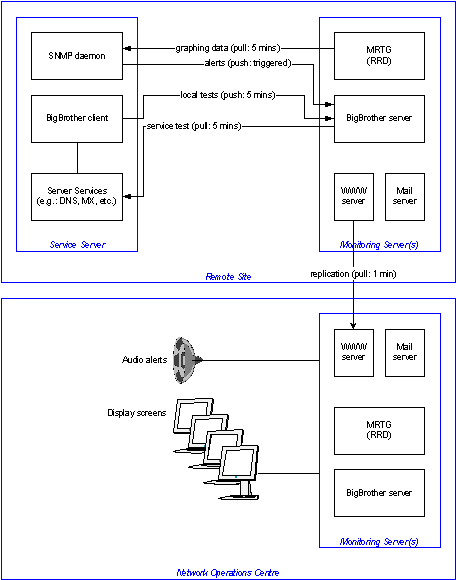
Figure 56: Control flow for System Monitoring
Big Brother
On each monitored machine is a Big Brother client that is configured to monitor the systems specific requirements to that service. (See Table below) Some of these tests are custom extensions written and implemented by GNR and will not be found in the standard package.
|
|
bbd |
conn |
cpu |
dig |
disk |
ftp |
http |
msgs |
procs |
qlog |
smtp |
ssh |
telnet |
|
DNS |
- |
Y |
Y |
Y |
Y |
N |
- |
Y |
Y |
- |
- |
Y |
N |
|
WHOIS |
- |
Y |
Y |
- |
Y |
N |
- |
Y |
Y |
- |
- |
Y |
N |
|
MX |
- |
Y |
Y |
- |
Y |
N |
- |
Y |
Y |
Y |
Y |
Y |
N |
|
WWW |
- |
Y |
Y |
- |
Y |
N |
Y |
Y |
Y |
- |
- |
Y |
N |
|
FTP |
- |
Y |
Y |
- |
Y |
Y |
- |
Y |
Y |
- |
- |
Y |
N |
|
SYSLOG |
- |
Y |
Y |
- |
Y |
N |
- |
Y |
Y |
- |
- |
Y |
N |
|
MON |
Y |
Y |
Y |
- |
Y |
N |
- |
Y |
Y |
- |
- |
Y |
N |
Table 1: Big Brother monitors (client/server)
The client does all the internal system checking and reports the status to the server at regular intervals. If there are any problems detected with any tests the client will immediately alert the server. The server is also aware that if it does not get the periodic green light reports from any hosts that there is probably a more serious issue to deal with. Some tests such as ‘disk’ and ‘procs’ are configurable further. The ‘procs’ test makes sure that certain processes are running/not running and can even alert us if the number of instances of a processes reaches upper/lower limits. These may also be set at different levels and for different processes on each machine. For example on each DNS machine we ensure that only 4 (four) named processes are running at any one time. Any machine running more or less than this threshold will cause the ‘procs’ test to be in error and an alert of the appropriate level will be triggered to all Operations staff. The monitor server will send emails and generate the appropriate web content. Audio alerts will be heard in the Operations Centre in the case that the team is unable to receive email.
The server side of the system runs network tests, generates content in HTML/WML and alerts Operations staff if there are any issues. The basic network tests are standard TCP connection tests and any TCP service can be tested in this way.
MRTG/RRDtool
The combination of MRTG and RRDtool is very strong. MRTG is used to mine the statistical data from the servers and store it in RRDs. MRTG’s own graphing capabilities are by comparison rather unimpressive compared to RRDtool’s. (See subsequent figures)
Figure 57: Example of MRTG generated graph
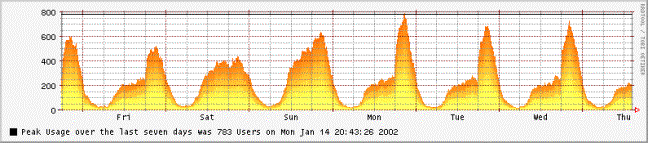
Figure 58: : Example of RRDtool generated graph
Phase II System
The planned improvements for the phase II monitoring implementation bring many additional features. Data security will be increased internally by using SNMPv3 protocol for all SNMP traffic. This will allow a high level of encryption on the packets. Statistics will be available in real-time in addition to a more comprehensive monitoring console. The real-time analysis will be used for closely watching trouble areas during fault analysis and for closely monitoring highly critical activity. This interface will be developed by GNR in Java.
Netsaint (http://www.netsaint.org) will most likely supersede Big Brother as primary monitor although BB will still be run in parallel and communicate with Netsaint.
2.11.3 Mapping components to hardware – Deployment view of the Error Handler package

Figure 59: The Error Handler, deployment view
The Update Handler offers an interface to the Error Handler, where Error MQ messages are pushed. The Error Processor polls these messages and carries through the actions described in the subsection below.
2.11.4 Control flow – process view of the Error Handler package
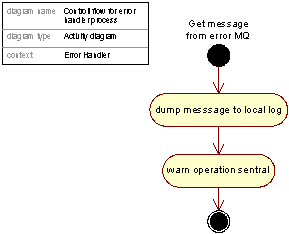
Figure 60: Control flow for the Error Handler, process view
This section presents the table structure of the Authoritative Registry Database. The authoritative data is used for most or all of the previously described services applied in the SRS, and some of the authorative data is replicated to the external services, like Whois, DNS and zone file access.
The following table structure is a proposed structure for how the .org data may be structured internally in the database:
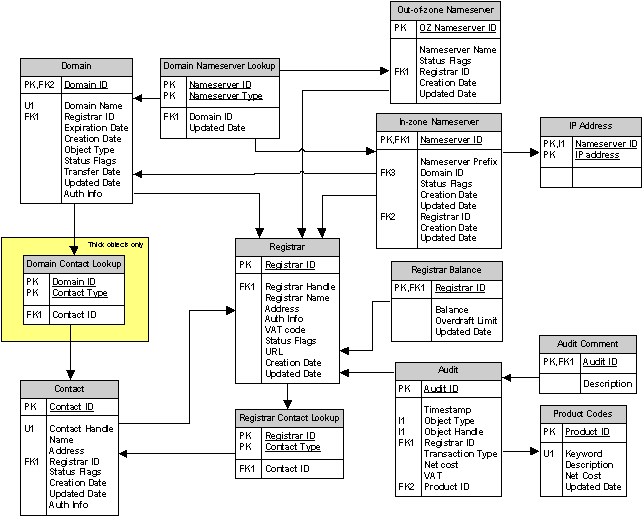
Figure 61: The table structure of the Authorative Registry Database
GNR anticipates moving the .org database from its current structure, a so-called “thin” database, where no contact information is stored, to a “thick” database, where contact information is stored with each object. The thick database structure has a number of advantages for the community, as explained in Section C18 to this application. Section C18 details how the transition of the database from thin to thick will happen.
Additionally, when “Thick”, the database will store information on the registrant. This will include name, address, telephone and email. Other details pertaining to the registrant’s financial status with the Registrar are not to be stored by the Registry Operator, thus allowing the Registrar to registrant relationship to remain private. The Registry Operator will additionally store similar data, where applicable, for the administrative, technical, and billing contacts.
Please consult Section C17.3 for further descriptions of the database capabilities.
This section describes the location, connectivity and environment descriptions of the GNR systems, including descriptions of the buildings, environmental equipment and Internet connectivity.
Hardware and software systems operated by GNR are described in the previous parts of Section C17.1, in particular under Design view (which details software structure and systems), network (which details the server park, setup, internal network topology).
The following section describes the environment of the GNR servers and systems as found in the GNR hosting center(s).
Structural attributes of Hosting Centre
· A multi-story, 250,000 sq ft total building area
· The data centre has a total area of 11,842 sq ft
· Foam roof with Fire Extinguishing system, supply/extract ducts, chillers & water pumps
· A water/leak detection and light protection system
· 24/7 on-site, in-house security guards
· Card readers
· Centrally monitored, recorded video surveillance
· Anti-terrorist glass
· The ceiling is 3m above the floor tiles, with 600mm of under-floor space
· Cable trays lie under the floor tiles, and hold the signal cables, and the power cables lie on the floor
· 19 security cameras (expandable to 32), which are centrally monitored, digitally recorded. Recordings are kept for 3 – 6 months
Redundant Power Systems
GNR has redundant power supplies to all of its servers. Each server, ESS and Foundry switch and other equipment has 2 independent power feeds and are additionally connected to UPS (battery based power), which will keep servers running for up to 3 hours while generators are starting up. All hosting centers where GNR hosts its servers and equipment have generators located in the building and fuel storages locally for up to 3 days of power failure, after which fuel deposits must be replenished from external sources
Other power parameters of the building in which GNR is hosted are:
· 7.5MW is required into the building for the full power design load
· 2 utility company feeds (from separate substations – each feed being 11MW and 4MW)
· There is a 50 hour full-load run time without refuelling
· There are 6 Generators of 1500 KVA each
· Running on Diesel fuel with cleaning system
· The tank set-up is:
o 3 x 24,000 litre tanks
o 5 x 1000 litres/day tanks
· There are 3 UPS units, each with 400 KVA and maintenance wrap-around
· The configuration is parallel, and there is one source input to the UPS
· There is 20 minutes of battery back-up at full design load
Airconditioning parameters
· There are 5 ‘Carrier’ Chillers, each of 1225kW
· We have 2 chilled water loops to the data centre, although the center would maintain maximum output if one of the chillers were has an outage
· There are 2 chilled water pumps on each loop, with only one being required on each loop for maximum design load
· The chillers have their own dry coolers
· There are 2 condenser water pumps
· One condenser water pump is required to maintain operation at maximum design load
· There are 11 ‘Uniflear’ HVAC units serving the data centre
· The redundancy level is 9 + 2
· Each HVAC unit weighs 20 tonnes
· Each HVAC covers one zone
· The air is injected into the room via floor grills
· The maximum heat dissipation for a 5 rack cage is 7.5kW exc. external sources
Fire protection systems
· We employ a Very Early Smoke Detection Alarm (VESDA) along with other conventional smoke detectors, and use Argonite above and below the floor level for fire suppression
· Smoke detectors are installed below the floor, and heat detectors are both above and below the floor. A smoke purge system is also installed.
· FM-200 Fire suppression system which does not harm electronic equipment and is safe for humans, unlike CO Systems which can suffocate humans who fail to leave promptly upon hearing the signal.
Cabinets
· The Rittal cabinets measure 800mm (D) x 600mm (W) x 2050mm (H) (42U)
· The load capacity is 400kg, and the maximum capacity for the facility is 470 (336 floor; 14x5-cab cages, 1x10-cab cage and 1x54-cab cage)
· The power is brought into the cab via 2 x 16amp Commando style sockets (one for A side and one for B side)
· We use By Crypto style locks for front & rear of the cabinets, with keys & card keys for the cages
Redundancy
All servers run dual network cards, and there are redundant LANs in every server location. Should a network card or an entire LAN fail, the network and services on the network will continue to operate unhindered.
Multiple Server locations and bandwidth providers
GNR will operate 5 server locations for the operations of .org. Three of these will be the same locations powering .name currently, the latter two will be two new hosting locations that GNR will set up (will not be outsourced) in the US for the purpose of .org DNS.
The diagram below illustrates the GNR locations:
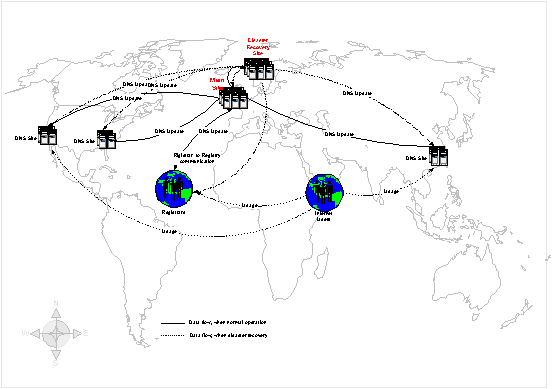
Figure 62:geographical spread of GNR locations
|
UK |
Norway |
Hong Kong |
USA 1 |
USA 2 |
|
|
Bandwidth |
2x100Mbit |
34Mbit |
10Mbit |
2Mbit |
2Mbit |
|
Provider |
GlobalSwitch Colt |
MCI WorldCom |
NTT |
MCI WorldCom |
Level 3 |
|
Status |
Currently fully operated and owned by GNR |
*Currently outsourced, but will be wholly operated by GNR for .org |
|||
Table 2: Internet connectivity on GNR hosting locations
Disaster recovery site
GNR operates a full subset of all services on a Disaster Recovery Site. As shown in the diagram under “Server Locations” in this document, the Disaster Recovery Site is operated in Norway. GNR has personnel in place, both operational and development, to ensure that the Disaster Recovery Site is ready to take over the main operations at all times. Should a failover to the Disaster Recovery Site be necessary because of the UK main site going down, all services, including SRS, Whois, update services, data validation, MX (for .name), etc, will be run from Norway. However, the capacity of the Disaster Recovery Site is not as high as the UK main site, as the table above indicates. However, it will ensure that operations run continuously without interruption even in the case of catastrophic failure of the UK site.
GNR has both tested failover to the Disaster Recovery Site, and done a real failover from UK to Norway of all services (as described in more detail in Section C15 to this .org Proposal) and knows well the challenges involved. However, both testing and real failover has worked successfully and has not resulted in any downtime or loss of authority of any of the GNR services.
Triple database servers and centralized database storage
The Registry database is running on three separate database servers each running Oracle on the IBM operating system AIX, an extremely stable combination. The database data for each server is stored in the ESS, an internally mirrored storage solution, running RAID on each internal storage structure. This double duplicity gives extended security.
Using three database servers, each with dedicated tasks, is a massive protection against outage. As described further in section C17.3 to this .org Proposal, the dedication of each component results in higher performance, higher security, higher consistency between databases and external services, and increased error correction/detection and consistency checking.
Hardware encrypted communications with Registrars and external DNS servers
All communication between GNR offices, GNR UK hosting center and GNR Disaster Recovery Site is strongly encrypted with a Netscreen 204 VPN link and protected against eavesdropping and/or decryption.
Facility security including access control, environmental control, magnetic shielding and surveillance.
The physical security of the hosting centers is important to prevent system outages. These security measures are described in more detail in this proposal’s Section C17.9.
Further, the physical conditions in the hosting centers are important to prevent system outage. GNR assures the following in its hosting centers:
· 24 hours monitoring of the physical environmental factors, including temperature, humidity, power, security systems, water detection etc. If any system is found to be operating outside normal working parameters, the on-site staff will investigate and arrange for the appropriate service or maintenance work to be carried out.
· Redundant air-conditioning capable of maintaining the environmental temperature at 20°C ± 5°C and humidity between 20% and 65% suitable for server equipment.
· A fully automatic fire detection and alarm system that is linked to automatic suppression systems is required, with the suppression system based on Argonite (or similar).
· Smoke, fire and water leak detection systems
· UPS/CPS power feeds that ensure 99.99% power availability through battery and generator power back up supplies
· Heating, ventilation and air conditioning systems
· FM-200 Fire suppression system which does not harm electronic equipment and is safe for humans, unlike CO Systems which can suffocate humans who fail to leave promptly upon hearing the signal.
Focus on top class hardware, standardized on few different products from solid vendors
By focusing the hardware to certain well-proven series, the Global Name Registry will operate a minimum of different hardware making it easier to maintain, replace, install, upgrade and secure. Top class suppliers have been chosen to provide the best of breed solutions.
GNR draws extensively on IBM hardware and has a very close relationship with IBM. All GNR servers are stable and well-known configurations of IBM hardware, and the GNR team is experienced and confident in setting up, modifying and trouble-shooting the IBM hardware.
GNR uses the network equipment from Foundry, which takes the network to the next level in terms of quality, reliability and speed. The Foundry network equipment is described in more detail in Appendices 22, 23 and 24 to this proposal.
See sections C17.9, C17.13 and C17.14 for further details on security, hardware and standardization.
Other miscellaneous provisions of the hosting center
· Deliveries can be made 24/7 (with prior notification)
· There is a goods lift of 2m x 2.5m x 2.3m (w x d x h), load capacity of 2500kg (useful for the 1.2 ton GNR ESS)
· There is a skip on site, for removal of rubbish, providing there are no hazardous substances
· There is a refreshment café on site, which is open from 8am to 3pm from Monday to Friday. Outside of these times, there are vending machine facilities (very useful for night works on the GNR site)