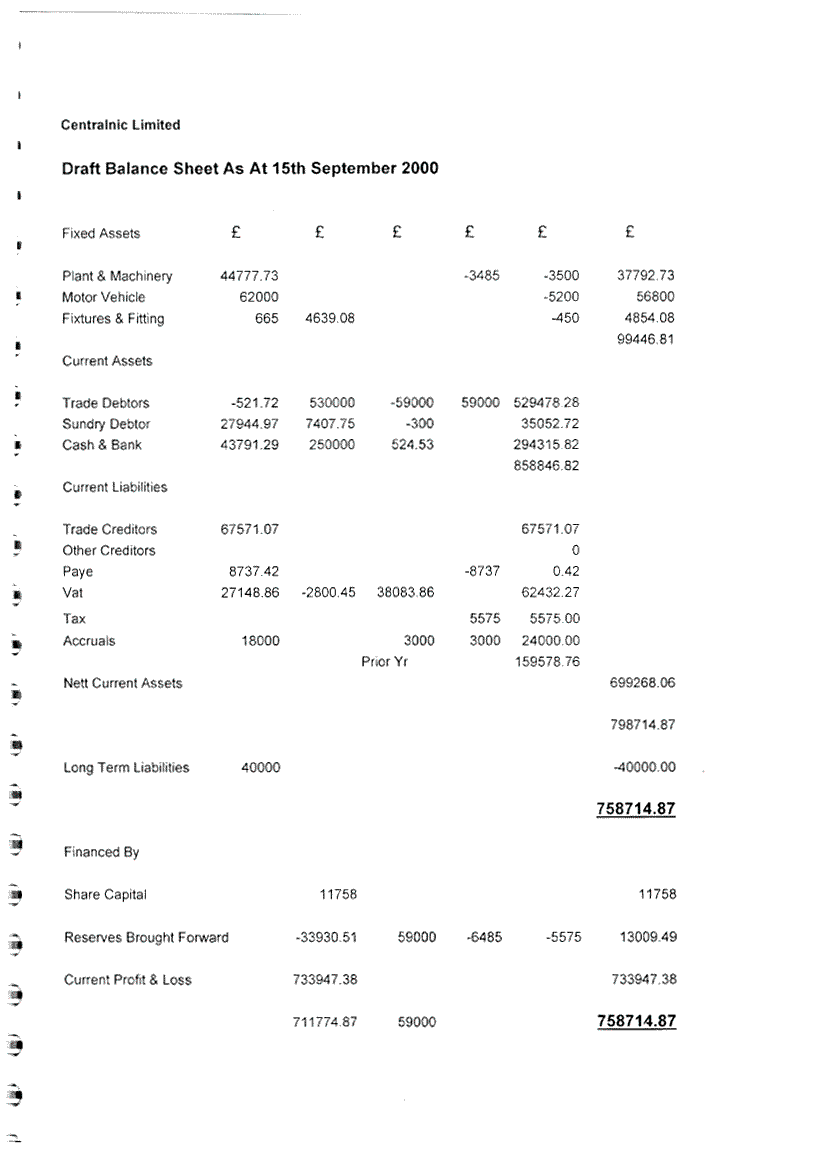
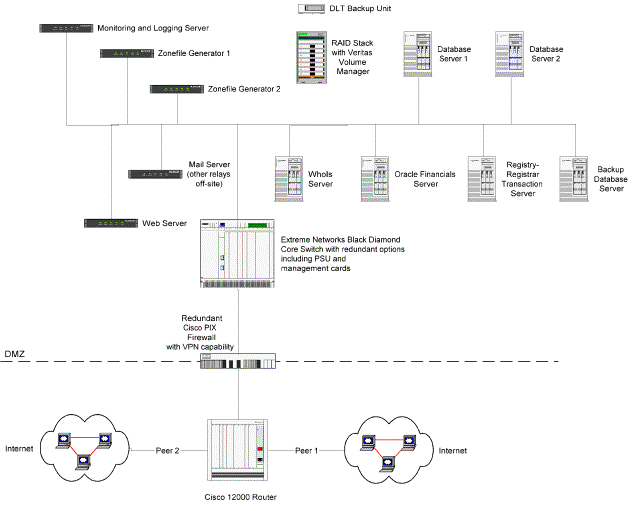
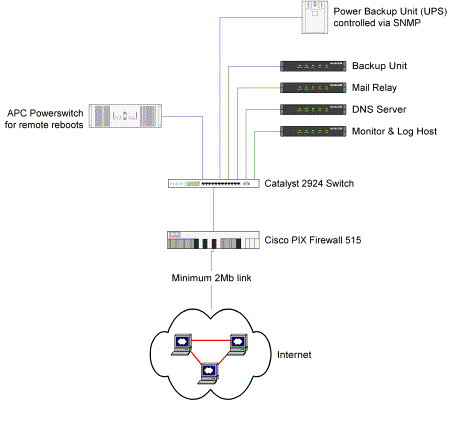
Zone files are
distributed via a secure point-to-point tunnelled virtual private network (VPN)
to each location, and verified through periodic independent checksum utilising
a tripwire-style approach. Connection requests generate a one-time 128-bit key
utilised over an SSL link to circumvent network scanning. Refreshing of zone
files and DNS reload are initiated by the core zone file generation machines
every 24 hours maximum.
Distribution is
initiated by the core zone file generation machines "zonehost-1" and
"zonehost-2". Generation is split over the two machine equally, and
logged remotely to the monitoring and logging host.
For access to
zone transfers to be approved, it is envisaged that the requesting body must
agree to a contract restricting use of the data in order to prevent usage such
as unsolicited commercial email, etc.
CentralNic is
committed to using the DNSSEC protocol as it becomes available from the root
nameservers.
The financial
system chosen is Oracle Financials, due to its multi-user capabilities, platform
independence, scalability and close relationship with the Oracle database
itself. This enables the Console system to link in and provide instant
statements of account, the ability to secure payment online, and seamlessly tie
in with the general ledger.
The reporting
structure of the Oracle Financials system is such that it is provided through a
web interface - therefore the reporting can be integrated within the Console
system, supplying live key performance indicators to management, and optimising
project execution. Most, if not all financial reports will be generated by the
Oracle Financials system.
The core server
for the Financials system is a high-specification Sun Enterprise 420R server,
described earlier in section 15.2.1. It is secured behind the Cisco PIX
firewall, and any reporting/manipulation will only be permissible through the
VPN to authorised personnel, administered via a username/password arrangement.
The current
CentralNic system allows for an automated setup of invoicing, reminders after a
preset period, withholding of domains, and subsequent deletion.
D15.2.7. Data escrow and backup.
·
Daily
backups.
·
Configs
+ Data from all critical servers is pulled off on a daily basis.
·
CVSDB.
·
Mail
config.
·
Majordomo.
·
Homedirs.
·
websites.
We are investigating total on-the-fly
backups of the database using software designed for the purpose. This will
allow us to maintain a real time copy on a separate machine that can be used to
transaction rollback if necessary - this is unlikely but we prefer to work on
the "prevention is better than cure" rule.
Restoration Capabilities and Procedures
The ability to restore data to any
machine is highly dependent on it having a network connection. If a machine
suffers total failure, which can be replaced in a very short time, it is
possible to do a minimal install to that machine and then to restore from
backup in a short period. In the meantime other machines will continue the work
of the failed unit, so customers / clients should never see any problems. Tasks
may take slightly longer to execute, depending on which machine fails, but the
end result is hopefully a totally resilient solution.
24 hour paging and support staff will
alert senior staff to any problems as soon as they are noticed - problems are
usually picked up inside a couple of minutes of occurring, by the automatic
systems in place.
Senior staff are on call at all times
and if support staff cannot resolve a problem in a defined period of time, they
will follow procedures to bring senior staff out to resolve the issue. It is
not possible to give a guaranteed time of fix for all problems, as the nature
of a problem may make it more difficult to solve than at first thought, and may
leave issues outside of our control, such as acquiring replacement hardware.
On the issue of replacement hardware,
we aim to have backup cluster units at our premises ready to "slot
in" in the event of UK problems. Any problems in Global locations that
result in hardware failure or otherwise will be solved as soon as physically
possible - if we establish that an entire global location has suffered hardware
failure (a very unlikely event), the first response will be from support or
technical staff, to keep services running on alternate machines in different
locations. If the problem is hardware failure, a replacement unit or units will
be sent out to the affected location and a member of senior technical staff
will go to the location as soon as physically possible, to replace the units
and restore service to the area. We aim that due to resilience within our network
and our systems, that other units will take over the job of the failed units
almost immediately. However, there may be a short period of downtime while the
backup units take over the job of the failed units, but we will use our best
endeavours to ensure that any downtime is keep to an absolute minimum.
Backup Methods
There is a daily backup of system files, as shown above -
these are rotated, such that we have data rolling back at least a week.
Off-site backups are made by archiving and transferring the
same backup files to a location which is physically nuclear warfare safe - see
http://www.thebunker.net for information. A cluster of servers within this
location caters for resilience and redundancy within the backup facility. We
are also investigating off continent backups either by DLT transfer by carrier,
or by file transfer to off site servers.
D15.2.8. Publicly accessible look up/Whois
service.
Every domain
name registry should operate a Whois service conforming to RFC954 to allow open
and clear access to domain objects within a database (subject to local data
jurisdiction laws), and CentralNic is no exception.
Whois queries
are handled by a separate Whois server: a Sun Enterprise 420R which queries the
live database directly. The net effect of this is that the Whois data is kept
completely up-to-date - a system at CentralNic which has been proven in a
production environment.
The Whois daemon
software is a multithreaded daemon application written in C. Unlike most other
Whois daemons, it is stand-alone (not spawned from inetd).
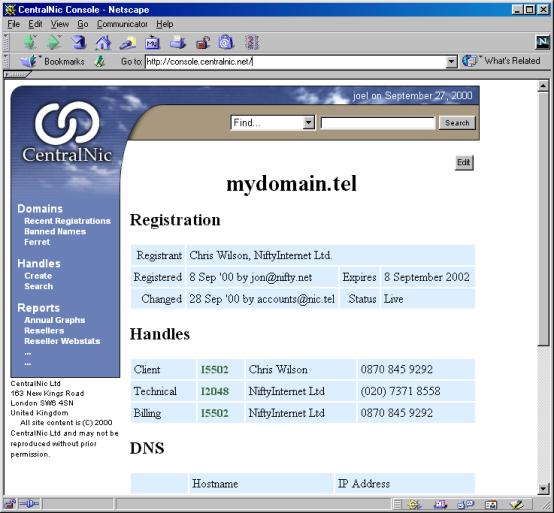
Responses to
Whois queries look like this:
Domain Name: MYDOMAIN.TEL
Registrant: Mailbox Hostmaster, Mailbox
Internet
Client Contact, Billing Contact:
(I5502)
Mailbox Hostmaster
Mailbox Internet
163 New Kings Road
Fulham
London SW6 4SN
United Kingdom
Email: names@mailbox.net.uk
Tel: 0870 845 9292
Fax: 0870 845 9293
Technical Contact: (I2048)
Joel Rowbottom
Mailbox Internet Ltd
163 New Kings Road
Fulham
London SW6 4SN
United Kingdom
Email: joel@mailbox.net.uk
Tel: (020) 7371 8558
Fax: (020) 7736 9253
Record created on 8 Sep 2000
Record paid up to 8 Sep 2002
Record last updated on 28 Sep 2000
Domain servers listed in order:
DNS.MAILBOX.CO.UK
195.82.96.40
NS1.MAILBOX.CO.UK
195.82.96.6
--
This whois service is provided by
CentralNic Ltd and only contains information
pertaining to Internet domain names we
have registered for our customers. By
using this service you are agreeing (1)
not to use any information presented
here for any purpose other than
determining ownership of domain names (2) not
to store or reproduce this data in any
way. CentralNic Ltd - www.centralnic.com
Under the CORE
system many registrars do not maintain their Whois server in a production
environment, nor keep it up-to-date for referral through the "Referral
Whois" system detailed in RFC2167. Bearing this in mind, the Whois queries
will be centralised. This is not to say that referrals will not happen to the
centralised Telnic server, but centralisation will remain the key to a reliable
service.
In order to
minimise abuse, a constraint will be placed upon the number of queries which
may originate from one particular IP address over a single 24-hour period: this
method has been implemented by several registries and is an effective way of
combatting what effectively amounts to a denial-of-service attack. Queries may
also be performed from the Telnic website, and will be similarly limited.
Options to the
Whois system are in line with RFC1834: "Whois and Network Information
Lookup Service, Whois++", and related RFC documents RFC1835, RFC1913 and
RFC1914.
Additionally, a
second more restrictive Whois will be installed to provide domain object access
in XML format, to the specification given in section 15.2.2.
D15.2.9. System security.
We take every step to
ensure the security of our systems. This comprises hardware security for the
servers, network security in the form of multiple firewall layers, and also
physical security in the form of access restrictions at the facility centres
that host our servers.
Hardware Security / Physical Security
Hardware security and
physical security tie in together very closely. All of the servers that handle
our network are in locked cases - which in turn are in locked cabinets, in a
locked cage, within the facility centre. The only people with access to the
cage that our equipment is kept in are the facilites staff, and senior
technical staff of the company. This rule is very strictly applied. Indeed -
many of the colocation providers restrict the access to their own rules - in
most circumstances anyone wishing to have access to any of the CentralNic
servers would need Photo ID, which has previously been communicated with the facility
staff by an authorised contact. Otherwise, the person would not be allowed into
the facility. In addition to this, most of the machines are in locked cases
situated in locked cabinets. The same rules apply here - only senior technical
staff and the facility staff have keys for the cabinets and also for the
machine cases. This ensures that no-one can just walk into the facility centre,
into the cage, open the cabinet, and tamper with the machines.
Facility centres are
fully power protected, and also have fire detection and control systems, in
addition ot full environmental monitoring and HVAC Air Conditioning Systems.
Most centres are also earthquake-proof - enabled by seismic bracing within the
structure of the building itself. This is more prominent in earthquake prone
locations, but most centres have this level of protection.
Full audit trails are
available from the provider at any time - this ensures that actions taken can
be traced. Everything is recorded - date and time of exit and entry, the escort
to the cage, what was taken in and out in terms of hardware, and technical
staff will keep a record of actions taken and work carried out on systems.
Network Security
Access to machines over
the network is the biggest single point of access, and hence, the one that
requires the most protection. To this end, we employ hardware firewalling
technology from Cisco Systems, which also provides us with network access
control, and another layer of traffic logging.
Cisco Pix Firewall
We use Cisco Pix Firewalling
units at each location of servers to provide full hardware protection - these
units are completely self contained and thus maintainence free. By using
multiple units, not only do we get failover / redundancy of the firewalling,
but also we get the ability to reroute traffic between machines seamlessly. The
units communicate with each other over an encrypted connection - this allows us
to effectively set up a totally private internal network for all of the global
servers whereby the firewall hardware handles the address translation and
routing of traffic.
We utilise 2 units in
each location for redundancy. These units are effectively configured to run in
the same state at all times by communicating directly across a local channel so
that if one unit loses network connectivity, Power, or has a failure, the other
unit may take over with minimal disruption to services.
In combination with
managed switches, this provides us with a fully redundant hardware firewalling
solution, and with the VPN features of the PIX hardware, we have a highly
secure method for transferring sensitive network traffic. This is especially
useful for network logging facilities, and also transfer of data to a machine
dedicated for backup purposes, as all the data is transferred over a secure
connection. All traffic that does not originate from a public internet
connection is encrypted, thus protecting the intellectual property within the
data, as the database is never transmitted in the clear or revealed to the
outside world.
Performance
The Cisco Pix units that
we utilise can handle 125,000 simultaneous connections - given that most Unix
and Linux machines can only handle 65,000 connections at once, it is very
unlikely that the units will be overloeded. We would be more concerned about
other hardware, such as routers, which would probably not withstand such load -
we will do everything we can to prevent problems in this area. The PIX product
does have "floodguard" technology, however, which is designed to
prevent such things as the recently publicised "Distributed Denial Of
Service" attacks on high publicity sites.
The main role of the Pix
units, however, is not to provide failover, but to provide firewalling. To this
end, all traffic from the internet that is not coming over the encrypted link
is highly restricted. On the server side, only database ports will remain open
to a restricted set of sources. At DNS server level, Pix firewalling in
combination with software restrictions will secure the DNS servers from
unauthorised access attempts.
Passwords / Access
All server passwords are
changed not less than once every 2 weeks. Additional methods of authentication
are used - for remote access, SecureID and/or Cryptocard technology ensures
that only authorised senior technical staff have access to the machines, by
requiring a hardware based token authentication. Such hardware tokens guarantee
that passwords are only valid for 2 minutes at a time, thus greatly reducing
any risks in the unlikely event of traffic being intercepted, or of passwords
being stolen. In addition to the token code, a user PIN is also required. In
the event of a token being lost or stolen it can easily be rendered useless by
setting an option on the authentication server. This solution has the added
benefit of logging all attempted logins on the authentication server.
All sensitive traffic on
the network will be encrypted where it traverses untrusted networks, as
described above. This makes it impossible for a hacker to sniff passwords in
transit over the network and use them to access machines in an unauthorised
manner. Also, machines will be configured to only allow connections from
certain sources, so an attacker would have to already be on the network, and
have a password, and a hardware authentication token, to move across the
network. This allows legitimate access with no problems, but unauthorised
access is very difficult.
New passwords are
communicated to facility staff only if absolutely necessary. Console logins
only require a username and password, as it is impractical to give facility
staff hardware tokens to perform remote maintainence if required. We intend
that we will be able to do everything remotely, as the combination of a
Terminal Server, remote power switch, and network access, ensures that there is
effectively nothing that cannot be done remotely that could be done at the
machine console, except in the case of hardware or provider connectivity
problems. Procedures for dealing with hardware problems are described in the
System Reliability section.
D15.2.10. Peak capacities.
Peak capacities cannot accurately be
predicted as hardware and software will not be in operation until the
alpha-test stage.
Given the nature of the potential
for a new top-level domain name and unavailability of prior application data,
it would not be prudent to attempt to predict peak capacities at this stage.
However, CentralNic is confident the systems specified are scalable to an upper
ceiling of 10,000,000 registrations based upon it's own experience in the
domain name market.
D15.2.11. System reliability.
Backup and coverage for outages is
addressed in this proposal in sections 15.2.11 and 15.2.12. It is worth noting however that in the event
of a multiple catastrophic failure of our internal systems the front end of the
registry is a queueing system which can store up to 3,906,250 registration
applications in appropriate chronological sequence.
In the event of a major failure of
all access to our systems (for example a major failure of a portion of the
Internet itself), applications are handled by the standard email system which
would indicate non-delivery to the initiating registrar.
In the six years during which we
have been operating this situation has never affected our main systems,
although local outages can obviously cut off individual registrars or
resellers. Cover for such situations
has to be the responsibility of the local operator since we cannot detect them
or circumvent them.
It is the aim of the Registry Operator to provide a service
24 hours a day, 7 days a week, 52 weeks a year. We set very high standards and
use all resources we can to provide customers with the service they expect.
To this end, we only use high quality
systems from suppliers such as Sun, Network Engines, and Cisco Systems. The connectivity for the
global network comes from suppliers with a proven track record in providing
high quality service and high availability to end users.
The connectivity suppliers monitor
their own systems and networks on a constant basis, which allows them to
provide us with the best possible service, which in turn allows us to provide
the best possible service to the users.
All implemented systems are, where
possible, fully redundant. At least 3 servers are installed in every location
world-wide to handle requests - not only does this speed up responses, as
traffic does not have to travel several thousand miles to it's destination and
back again, but also it allows us to provide a fully redundant service in the
case of hardware failure or otherwise.
Systems are configured such that a
machine will take over the job of a different machine in the event of the first
machine failing for any reason. We employ custom tools to suit this purpose,
along with specialised hardware.
Our systems are also continuously monitored
- all processes we run are checked every minute of the day. Any potential
problems are immediately flagged and support staff are alerted - monitoring
systems will try to fix any problems before technical staff are made aware of
the problem, but if this is not possible staff will be alerted immediately, and
will take appropriate action to resolve the issue.
Our tests have shown that under
normal use the reliability of our systems is very high - outages are kept to an
absolute minimum, and are usually resolved within minutes of being reported.
What do we monitor?
The automated systems on the network
monitor everything possible - right through from the basic "this service
is working" to the more advanced checking that data returns expected
values, temperatures / fan speeds / voltages from sensors built in to the
systems, that processes are running, and that network connectivity exists
properly.
Multiple redundant and distributed
monitoring takes place - it is quite feasible for a member of support staff to
see an overview of the status of the entire network from their desk at any time
of the day or night. If a problem occurs it will be flagged on this display,
and staff can then "drill down" into the particular machine with the
problem, identify what the cause is, and take steps to correct it.
If users see a problem which they
believe support staff are not aware of, technical staff are contactable 24x7 by
pager - there is a dedicated number to alert staff to a problem.
We keep a status page available to
the general public which is constantly kept up to date, so customers can verify
that we know about a problem and are working on it before they page us. This
keeps support staff from receiving a multitude of pager messages, all
describing a problem they already know about.
We do encourage people to let us know
if we report a problem as fixed and it is still not working correctly, as this
will improve our ability to resolve small problems before they turn into major
issues.
Data Validation
Data in the database will regularly
be validated and referential integrity will be checked on a constant basis by a
daemon installed on the database server cluster.
History Logging
Our monitoring systems keep a full
history of all events they record - processes going down, processes coming up,
acknowledgements by staff, etc.
This means we can pull out reports on
any system or service over a period of time. This also gives a complete history
of things that have happened - if a service breaks we can check the history to
see what has happened to that host or service previously.
D15.2.12. System outage prevention.
Our international network exists to
provide sensible and fast routing of DNS queries. It also provides multiple
redundancy.
It is worth noting that the total,
long-term failure of a single node does not, in fact, materially impair our
service. However, each location has full outage prevention systems as described
below.
We protect the systems we invest in
as much as possible. This includes such things as UPS cover for all parts of
our systems, hardware RAID to protect the integrity and availability of our
database and our servers, and hardware monitoring to ensure that any potential
problems are discovered early and can be resolved before they develop into
issues which will affect our customers.
Our Outage Prevention Measures are
described in more detail below:
UPS
We integrate UPS products from APC <www.apcc.com> - a proven
leader of high quality UPS equipment - to ensure that our servers keep on running
through power failures.
The batteries on the UPS systems will
keep our servers running for at least 30 minutes - this is in addition to the
power protection systems at each server facility. We anticipate that the
combination of our own UPS's with 30 minutes runtime plus facility systems will
mean that we never suffer a power outage.
The UPS sytems are complemented by a
MasterSwitch solution from APC - this allows us to selectively turn the power
on and off to any connected socket remotely. This gives us greater control of
our servers and allows us to perform almost all problem resolution remotely.
If a piece of software crashes for
whatever reason and hangs the machine, generally it is impossible for the
machine to be rebooted remotely - this would involve a call to the facilities
management staff, at cost, to reboot the machine. With this system in place we
can perform this task ourselves, quickly and easily.
Both the UPS systems and the
MasterSwitch systems are fully network connected - our monitoring systems are
capable of extracting information from both UPS and Masterswitch via SNMP
(Simple Network Management Protocol), an industry standard method for
extracting and using network data. We can tell at a glance what the power
status on a UPS is, it's runtime on batteries, it's temperature, etc - in the
event of a battery failure staff will be notified immediately, and as such can
schedule replacements / repair work to correct the problem.
Any problems with UPS hardware will
not cause outages to the servers that are connected. For example - if a battery
in a UPS fails, either due to manufacturing defects or through general use (UPS
batteries are quoted as lasting around 2 years) - the UPS will send out an
immediate alert, but will continue to power the systems connected to it. Staff
will arrange for a resolution to the problem immediately. Even replacing a
battery on the UPS systems does not require that the load on the UPS is turned
off - this task can be performed quickly and easily by any member of staff to
restore the unit to full use as soon as possible.
If the facility of a server loses
power for a length of time that requires operation of our UPS, staff will be
paged and alerted. If the power remains out for such a length of time that UPS
battery power starts to run low, then automatic software will shutdown servers
cleanly in turn, which allows us to keep at least one server running for as
long as possible before a power failure. In the event of all power to a
facility failing, monitoring systems will control the scheduled transfer of
servers
D15.2.13. System Recovery Procedures.
In the unlikely event of
a system outage occurring within the CentralNic network, systems monitoring
would alert support staff and senior technical staff immediately.
Procedure for restoring from an unexpected outage
If a catastrophic error
occurs on a server which causes failure of that server, the primary aim would
firstly be to ensure no loss of service to the customers. Once this has been
achieved, restoring the failed unit to a working setup is the next highest
concern. If it is discovered that a disk has crashed or failed, the unit will
be swapped out and a replacement, pre-configured unit will be swapped in as
soon as is physically possible. The failed unit will then either be returned to
the vendor on a 48 hour turnaround, or if the problem is small, will be fixed
as soon as possible. If a machine can easily be restored to working order, it
will be monitored closely by CentralNic Technical staff to ensure the problem
does not recur, then if all tests are OK, the machine will be swapped back into
service at a time that is not inconvienient to users. This is the primary logic
behind having at least 3 servers in every location.
Redundant / Diverse Systems
This section is covered
by section 15.2.12 - System Outage Prevention.
Recovery Processes
Due to the nature of
failures, it is impossible to describe a recovery process for each. As such,
all recovery will be undertaken using best endeavours, with the aim of restoring
service as quickly as possible.
Training of Technical Staff
Staff will be trained
in-house by Senior Technical Management to deal with potential recovery issues
as they arrive. There will be demonstration systems which will have to be
restored by the staff, under supervision, to gain experience in re-installing
the OS and performing a restore of files from the backup server. This should
enable backups to be undertaken by staff without senior staff supervision, but
should a machine fail and backups be required, the company will undertake to
have a member of Senior staff present to supervise and oversee the entire
recovery process, and to co-ordinate other services, such as failover to
secondary / backup units, liaising with component manufacturers, etc. If such
an event occurs a member of Senior staff will be called - there will be a rota
of Senior staff on call 24/7, to ensure availability.
Availability of software, operating systems, and
hardware needed to restore the system
If a server fails for any
reason, there is always a copy of the media containing the correct OS of that
server within the building. If a remote server fails, the member of staff that
travels to deal with the issue will also have a CD copy of the media. Hardware availability is pre-arranged using
service contracts with the manufacturers of the server equipment, i.e. Sun and
Network Engines.
Backup Electrical Power Systems
All facility centres have
redundant power supplies and UPS Units, which are supplemented by generators. This
provides a guaranteed service at all times. Servers are also protected by their
own UPS which will be in addition to any facility power protection, and will
provide a runtime of 2 hours on the core Database servers, and 30 minutes for
the global clusters.
Projected time for restoring the system
We estimate, based on our
own experience, that after we have restored a machine to a working state, it
should take no more than 45 minutes to restore
it to it's original status. This time is obviously in addition to any
hardware problems that occur, but redundant machines will continue the work of
the original machines while maintainence takes place. If a problem occurs with
a core database server, the projected time could be a lot higher than this. As
such, estimated recovery times are to be confirmed.
Procedures for testing the process of restoring the
system to operation in the event of an outage
Backup tapes and
procedures will be tested every month under supervision of a member of Senior
Technical Staff. This is to ensure that staff are kept up to date on any
changes in procedure that take place, and also any new technologies that may
have been implemented. This also ensure validity of backup tapes and offsite
backups.
Documentation kept on system outages and potential
system problems that could result in outages
In combination with
monitoring software, every outage is recorded into a database. Resolutions,
notes, comments, etc are all entered into this database also via a web based
administrative form - this allows management and/or technical staff to pull out
reports in real-time on any given service or host. In a similar fashion,
printed and typed documentation is stored containing details of potential
problems that could result in outages, how to check for them, how to fix them,
and what to do if the described method doesn't fix them.
D15.2.14. Technical and other support.
Availability of Support
There will be
the following methods of obtaining support:
1. "Delayed"
support requests, answerable on a non-urgent basis:
·
Email
·
Web form submission
·
Facsimile support
2. "Immediate"
support requests, for which staff must be allocated to cope with demand more
urgently:
·
Telephone support, providing low-cost or toll-free
numbers where possible
It is envisaged
that most end-user support will be carried out by registrars in their own
geographic regions, therefore language support will not be a major issue.
However, CentralNic already employ speakers fluent in English, Russian, German, Hungarian, Polish, Swedish,
French, Italian, Punjabi and Hindi.
Registrars will
be given their own particular contact name within the support department for
arising issues, to assure customer service continuity is maintained.
Logging Support Tickets
Technical help
will be logged via the ticketing system described earlier as Support Objects.
The following
flowchart illustrates the procedure when a call is logged:
Online Assistance
The support
given on the web site will be of paramount importance. In particular, we have
considered the following areas:
·
Frequently Asked
Questions
Compiled by the
support staff in response to the most popular queries, this documentation will
lower the level of support queries which need to be answered.
·
Support
Ticketing Status Reports
An area of the
web site which queries support tickets to retrieve status on whether support
requests have been actioned, and thus provide a quality service to the
enquirer.
·
Registrar/Registrant
Discussion Maillists
A means by
which the general public may discuss the ".tel" domain name, its
ramifications and its operation.
Support Staff
Since the
Internet spans many time zones and regions, front-line support will be a
24-hour operation requiring multi-lingual staff trained in the basics of domain
administration. Shift patterns will follow a 12-hour continental pattern, 3-on
3-off arrangement, spread over four teams. Through this mechanism there will
always be competent staff on-hand to assist registrars and end-users, and alert
the appropriate people in the event of a problem.
A support
database will be built up of symptoms, questions and resolutions to reduce the
need for highly trained technical staff on front-line support.
General Technical Staff
The following
positions will be 24-hour, rotational shift staff, with the given number being
immediately available at any one time:
|
Staff Position
|
Day staff
|
Night staff
|
On Call
(surplus to night staff)
|
|
Shift Team Leader *
|
1
|
1
|
1
|
|
Hostmaster *
|
4
|
2
|
1
|
|
Database Administrator *
|
2
|
1
|
1
|
|
Programmer *
|
4
|
1
|
1
|
|
Front-Line Support
|
30
|
30
|
0
|
|
Second-Line Support
|
15
|
15
|
0
|
|
Network Manager *
|
2
|
1
|
1
|
All core
technical staff members marked with an asterisk (*) above will be expected to
carry pagers and work to a callout rota, as defined by the Human Resourcing
section of CentralNic.
D15.3 Subcontractors.
·
There are no subcontractors.
ANNEX
SAMPLE CENTRALNIC EMPLOYMENT AGREEMENT
This employment and confidentiality Agreement
(hereinafter “Agreement”) is entered into as of the xx xx 2000
Between Centralnic Limited (“the Employer”) and xxx xxx (“the Employee”).
In consideration of the employment of the Employee by
the Employer, the Employer and the Employee agree as follows:
1. Position and Duties
The Employee’s title shall be “xxx xxx”, and the
Employee will report to xxx xxx or other such person as the Employer may
designate. The Employee shall perform any and all duties assigned to the
Employee by the Employer.
2. Salary
The Employer shall pay to the Employee an equivalent
salary of £xx,xxx per annum during a period of 3 months, starting from the date
the Employee starts to work full time for the Employer. After this period the
agreement will be subject to review. The salary will be paid monthly in arrears
and be subject to UK PAYE.
3. Hours of Work
The Employee shall work during normal business hours
with a one hour lunch break. The Employee undertakes to be in the office
between the hours of 9.00am to 5.30pm from Monday to Friday. The Employee
understands that there will be periods where longer work hours will be required
and has agreed that this will be acceptable.
4. Holiday and Holiday
Pay
The holiday year runs from 1st January to 31st
December each calendar year and the Employee’s holiday entitlement will be 20
working days per calendar year. In any event any holiday you wish to take is
subject to the approval of the employee’s manager. Up to five days holiday may
be carried forward and must be taken by 31st March the following year.
Pay in lieu of holidays not taken is only made upon
termination of employment. Holidays taken in excess of entitlement at the time
of leaving will be deducted pro rata from the Employee’s final salary.
5. Sickness
The Employee must ensure that the Employer is notified
by 9:30am on the first day of illness if the Employee is unable to attend work.
6. Periods of Notice
The Employee is required to give to, and will receive
from the Employer one month’s written notice of termination of employment.
Subsequent to termination of employment, the Employee
agrees to make themselves available for a period of one month in order to
complete any transition period and make information available to the Employer.
7. Disciplinary and
Grievance Procedures
The Employee accepts that employees who depart from
normally expected standards of work performance, timekeeping, attendance,
procedure, etc. will be liable for a verbal warning. If necessary this will be
followed by a written warning, and if the problem persists, a second and final
warning will be issued. If there is no improvement, dismissal with notice will
be implemented. A record of all warnings will be kept in the Employee’s
personal file.
The Employee accepts that employees who are involved
in gross misconduct, e.g. theft or embezzlement, breach of safety regulations,
will be liable to immediate dismissal without notice.
If the Employee has any grievance relating to this
employment, the Employee should raise it with their immediate supervisor either
verbally or in writing during normal office hours. If the matter is not settled
at this level the Employee may pursue it through the Chairman.
8. Security and
Confidentiality
The Employee shall not divulge or make use of any
confidential information concerning the Employer or its associated companies or
the products or services which may come to the Employer’s knowledge during or
after the employment with the Employer, without the express permission in
writing of the Employer.
All records, papers and documents, equipment, samples
or anything of the like nature relating to the Employer and its associated
companies or their clients, kept or made by the Employee, remain the property
of the Employer on termination of this employment and shall be returned to the
offices at that time.
9. Inventions and
Creations Belonging to Employer
Any and all inventions, discoveries, improvements, or
creations (collectively “Creations”) which the Employee has conceived or made
or may conceive or make during the period of employment in any way, directly or
indirectly, connected with the Employer’s business shall be the sole and exclusive
property of the Employer. The Employee agrees that all copyrightable works
created by the Employee or under the Employer’s direction in connection with
the Employer’s business are “works made for hire” and shall be the sole and
complete property of the Employer and that any and all copyright’s to such
works shall belong to the Employer. To the extent that such works are not
deemed to be “works made for hire”, the Employee hereby assigns all proprietary
rights, including copyright, in these works to the Employer without further
compensation.
Employees further agree to assist the Employer in
protecting or defending the Employer’s proprietary rights on all works.
10. Employee’s Use of
Company Facilities
The Employee agrees that any personal use of Employer’s
facilities will not be guaranteed and may be terminated at any time. In such
cases that the Employee’s personal use affects the service to paying customers
the Employer may request that some contribution be made towards the usage or
such usage be reduced.
Any use of facilities which is deemed to be
detrimental to the reputation or proprietary rights of the Employer may be
removed without notice.
11. Alterations
Changes in conditions of employment occur from time to
time and these will be notified by the Employer to the Employee in writing. In
each case these alterations will become operative within one month of the
change being sent to the Employee.
Agreement Signed and agreed as follows:
For Centralnic Limited
Name: Anil
Patel
Company
secretary/Accountant
Date: xx
xx 2000
Signature:
Employee
Name: xxx
xxx
Address: xxx
xxx
xxx
xxx
Date: xx
xx 2000
Signature: