The UIA Team has Documented Business Continuity Plans and System Continuity
Plans that outline the types of events that might interrupt operations and how
they would be addressed. The procedures for recovering from failures depend on
the nature, scope and severity of the failure. Figure C17.15-1 shows general
types of failures and the procedures that would be used to recover from them.
|
Failure
Type |
Recovery
Action |
Recovery
Mode |
| Failure of electrical power |
UPS maintains load until generators start |
Automated |
| Failure of UPS |
Redundant UPS takes over |
Automated |
| Failure of generator |
Redundant generator takes over |
Automated |
| Failure of PDU |
Redundant PDU takes over |
Automated |
| Disk drive failure |
RAID-1 mirroring in EMC |
Automated |
| Gateway server failure |
Other load-balanced servers take over |
Automated |
| Application server failure |
Other load-balanced servers take over |
Automated |
| Database server failure |
Hot stand-by server takes over |
Automated |
| Database failure |
Services recovered on alternate EMC device |
Manual |
| Failure of network provider |
Load shifts to other network providers |
Automated |
| Failure of secondary site |
Service continues at primary site |
Automated |
| Failure of primary site |
Service shifts to secondary site |
Manual |
Figure C17.15-1: Failure Types and Recovery Actions
Equipment supporting the .org registry is maintained at both the primary and
secondary data center facilities. Although the primary facility hosts the
primary database, each facility is able to assume full operations. Figure
C17.15-2 depicts the SRS architecture as balanced between the two facilities.
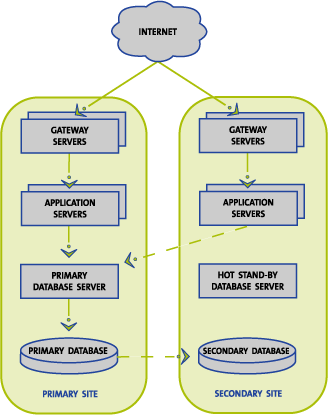
Figure C17.15-2: Redundant Site Architecture
Each facility contains a robust and redundant infrastructure, including
security, power, cooling, humidity and fire suppression (as discussed in Section C17.1 and
Section C17.13). Even if this infrastructure were to completely fail
at the secondary facility, it would not result in any outage of the .org
database. The secondary facility currently hosts the gateway and application
servers that facilitate a portion of the Automate Batch Pool. If this facility
were to be incapacitated, operations in the Guarantee and Overflow Pools would
be unaffected. Batch Pool activities would be restricted, although not entirely
curtailed, until additional servers could be added at the primary facility.
These additional servers already exist at the primary facility in the current
development and test environments.
A failure of the primary facility would mean that all services would run from
the secondary facility. The Secondary database would become the primary and all
RRP traffic would run through the servers at the secondary site. The operations
of the Batch Pool may be limited until additional gateway and application
servers could be deployed at the secondary site. The UIA Team's QoS function
would ensure that the .org registry database was not subjected to a greater
transaction volume than could be handled while still meeting all SLAs. Restoring
RRP service at the secondary facility, in the event of a complete failure of the
primary facility, could be done in less than eight hours. It would take a couple
of days to restore full Batch Pool capability. Since RRP transactions flow
through the secondary facility as part of normal business, connectivity to the
facility is assured. Periodic tests will be performed at the secondary facility
to ensure the ability to recover functions such as zone file generation and
Whois generation. Whois servers are currently divided between both sites so that
a site failure would not interrupt Whois service.
In addition to backing up registry data to multiple sites using multiple
media (as described in Section C17.7), backup copies of hardware configurations
and source code libraries will also be maintained. Because of the locations of
the two facilities, no additional staff will be required in the event of a site
failure. The UIA Team will maintain detailed statistics on system outages, their
causes, and their remedies. These statistics will be the basis for many of the
reliability and availability metrics discussed throughout this proposal.
Planned outages will be subject to detailed planning and testing in a
separate "staging" environment. In addition to validating all steps to
be performed during the outage, back-out plans are developed and tested.