Proposal by Questions:
C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 | C20 | C21 | C22 | C23 | C24 | C25 | C26 | C27 | C28 | C29 | C30 | C31 | C32 | C33 | C34 | C35 | C36 | C37 | C38 | C39 | C40 | C41 | C42 | C43 | C44 | C45 | C46 | C47 | C48 | C49 | C50 |
C17.15. System recovery procedures. Procedures for restoring the system to operation in the event of a system outage, both expected and unexpected. Identify redundant/diverse systems for providing service in the event of an outage and describe the process for recovery from various types of failures, the training of technical staff who will perform these tasks, the availability and backup of software and operating systems needed to restore the system to operation, the availability of the hardware needed to restore and run the system, backup electrical power systems, the projected time for restoring the system, the procedures for testing the process of restoring the system to operation in the event of an outage, the documentation kept on system outages and on potential system problems that could result in outages.
No single point of failure exists within the registry infrastructure. Common failure modes have been considered, and can be corrected rapidly and with minimal disruption to operations. Many failure modes result in automatic recovery with zero downtime.
Although the extensive redundancy and monitoring described above make a major system outage unlikely, Registry Advantage has created a number of contingencies for recovery from various types of failures. The complete replication of every component within the system and the highly resilient DNS network with multiple geographic locations means that even significant downtime events should not impact the ongoing operations of the system.
Several types of failure and the recovery mechanism are described below.
Database failure
A total of three database servers and three storage arrays provide cascading fallbacks and allow the registry to recover from multiple consecutive failures. The complete design of this database redundancy is described in C17.3. Registry Advantage will use software to detect and recover from failures in database hardware or the storage subsystem.
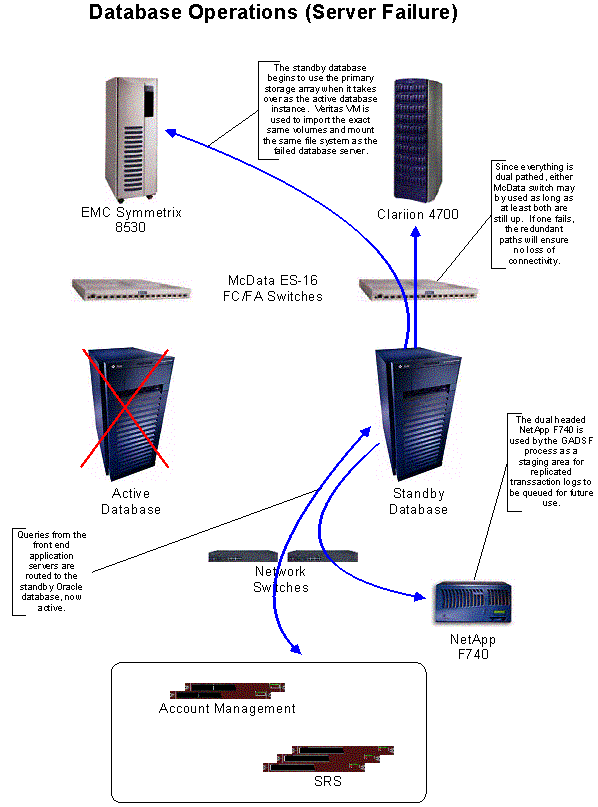
Figure 17.15.1 Database Operations (Server Failure)
In the event that the currently active database server should fail, but the standby database server and primary storage array remain operational, a simple database failover occurs. The standby database mounts the database filesystem that had formerly been used by the failed server, shuts down its standby database instance, and starts a new database instance using the primary storage array so that it can assume the role of the active database server. This is managed by Veritas Cluster Server software and recovers the database instance in less than three minutes with no data loss. This process is illustrated in Figure C17.15.1 above.
Storage failure
A description of database server modes is provided in section C17.3 above. Each of these database server modes is tied to a separate storage subsystem. At the primary location, the active and standby storage subsystems support the active and standby database server modes. At the alternate site, the backup storage subsystem supports the backup database server mode. Under certain failure conditions, the roles of these database servers and storage subsystems changes.
For example, if the active storage subsystem fails, however unlikely, the standby storage subsystem becomes active. If the primary site fails, or if cascading component failures cause a site failover, or if both the active and standby storage subsystems fail, the backup storage subsystem becomes active, and the alternate site becomes the active site, as described in our responses to Questions C17.1, C17.3, and C17.14 and depicted in Figures C17.15.2 and C17.15.3 below.
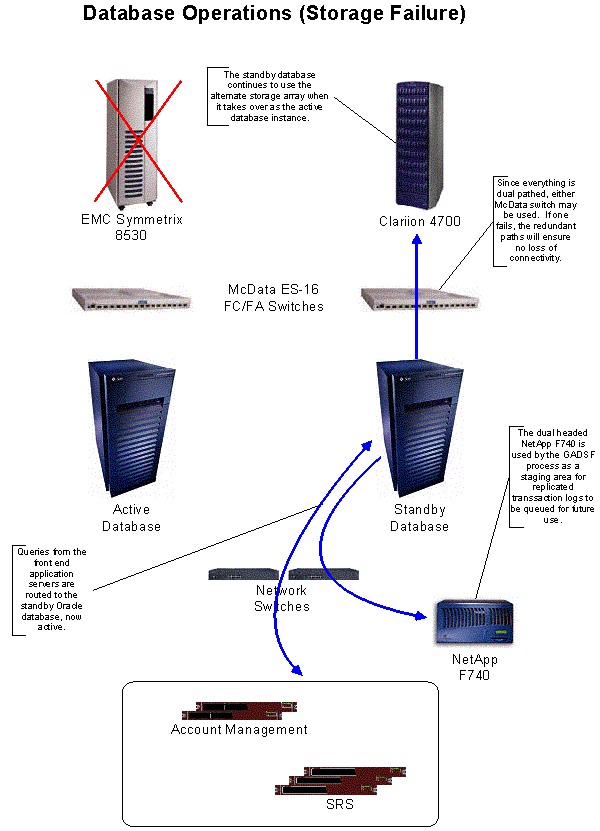
Figures C17.15.2 Database Operations (Storage Failure)
Server failure
Generally speaking, the failure of an individual Whois, SRS, or name server will not result in downtime. Registry Advantages layer-4 load balancers will rapidly detect these failures, stop sending requests to the failed node, and notify system administration staff, who can then repair the failed system without incurring downtime. Similarly, individual servers behaving erratically or in need of maintenance can be intentionally disabled at the load balancer and repaired.
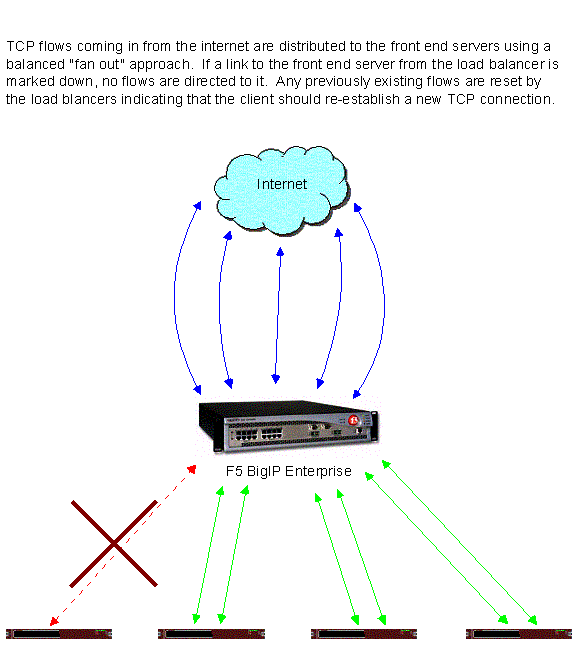
Figures C17.15.3 Database Operations (Storage Failure)
Cluster failure
In the unlikely event of the failure of an entire cluster of servers at the primary site, such as all of the SRS servers or the master DNS cluster, Registry Advantage could perform a controlled database failover from the active site to the standby site. Management software would facilitate the actual failover process. Upon completion of the failover, database operations and other registry functions would resume at the secondary site. In such an eventuality, this becomes a special case of the storage and data server related site failures described above. Registry Advantage specifically designed its server clusters to be highly redundant, however, so this scenario is extremely unlikely.
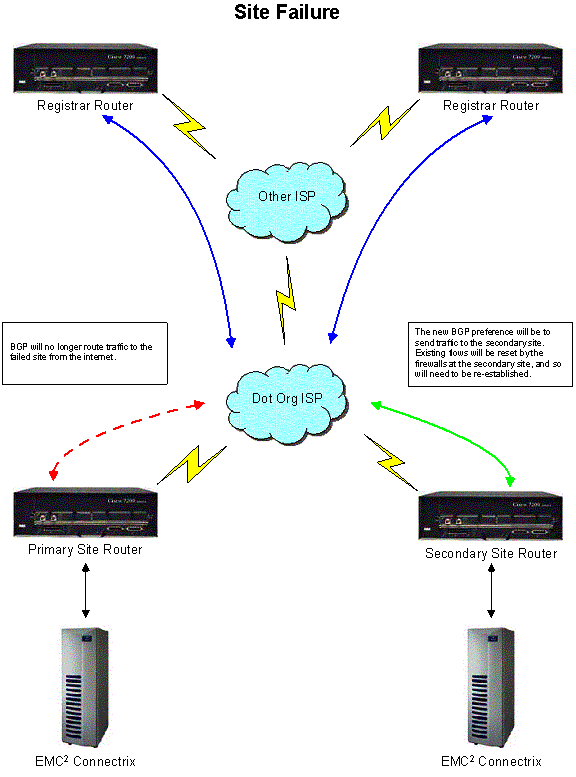
Figures C17.15.4 Site Failure
of any of the following application cluster pools in their entirety will result in a controlled site failover to the secondary site:
SRS -- if any of the supported protocol pools failed completely
AMI -- if the secure web based application pool failed completely and could not be restored within a preset time specific to this application
WHOIS -- if the entire set of WHOIS pools or any set of pools dedicated to a portion of the distributed cache all failed
Failure of any of these application clusters would not result in a site failover:
Cluster Masters -- all registry operations can proceed without the cluster masters for extended periods of time, so a site failover is usually not required
Systems and Network Management -- if any of these services failed completely, short term measures can be implemented until the cluster was restored
Development and Testing -- although these are critical to the ongoing operation of the registry, extended outages of these clusters could be tolerated without directly affecting registry operations
QAT -- like the development and testing clusters, these clusters could be down for extended periods of time without directly affecting registry operations
DNS -- the geographically distributed architecture and unique data distribution model implemented in the Registry Advantage DNS architecture allow for the entire cluster at the primary facility to fail, however unlikely, without impacting the globally distributed service
DNS Satellite Failure
Satellite DNS clusters may also fail. In that event, attempting to move database operations from the primary to secondary site is neither useful nor appropriate. Instead, by altering BGP route announcements , the IP traffic originally being sent to the failed cluster will be routed to an alternate cluster, which will answer requests directed at both its own IP addresses and those previously allocated to the failed cluster.

Figures C17.15.5 DNS Failure
Registry Advantage has also been conducting research into the use of using IP anycast [1] to provide its DNS system with improved redundancy and performance. Using this technique, the same IP address would be simultaneously announced from multiple PoPs, and each DNS cluster would be capable of responding directly to queries sent to any of these addresses.

Figures C17.15.6 DNS Failure (Anycast)
In the event that a site failed, any IP addresses in use at that location would be seamlessly re-routed to one or more other locations. In the extreme case, each DNS Satellite site announces BGP routes for all DNS PoPs and each cluster can respond directly to any query. Additionally, this architecture supports MxN redundancy by having more physical DNS Satellite sites than announced name server addresses.
Each cluster will also have a set of non-production IP addresses that can be used to administer the hosts in the event the BGP announcements for the PoP service IP ranges were stopped for any reason. Additionally, each server in a DNS cluster has a non-routable RFC 1918 private IP address for communication with the cluster master and the other cluster members. Communications between DNS Satellite sites and the primary site hosting the cluster masters is done over an IPSEC Virtual Private Network.
Network failure
The .org registry is built with extensive network redundancy. The use of high-availability techniques, such as HSRP and the spanning tree algorithm, mean that the failure of a network component will create no more than seconds of downtime before redundant equipment resumes the operation of the failed component. As described in C17.1, both the primary and secondary sites for the .org registry will have redundant connections to the Internet through diverse Internet Service Providers. Registry Advantage will use BGP to announce its space to each providers; in the event of the failure of an individual link or even an entire ISP, the Internets routing architecture will automatically redirect traffic through the other ISP. If both ISPs at the primary site should fail automatically, registry operations will automatically be moved to the secondary site.
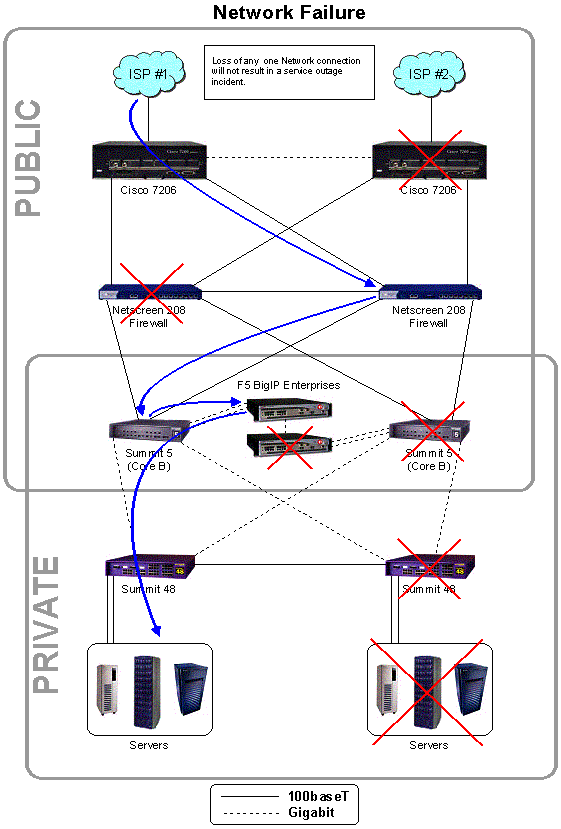
Figures C17.15.7 Network Failure
Power Failure
All sites will be protected by both UPS systems and generators to ensure continuous electrical power. Sites are additionally protected with on-site power generation capabilities. Generally, these generators will come on line automatically and provide power to the facility in the event of a complete failure of the local power grid. In the event of an unexpected power failure at the primary site despite these precautions, a failover to the secondary site will allow operations to be resumed within minutes of the failure.
Unexpected Failure
There may be types of failure that are not currently anticipated. These failures could be catastrophic and theoretically both the primary and secondary site could be affected. In order to protect against unknown threats, several disaster recovery contingencies exist:
- Because satellite DNS clusters do not depend on either the presence of a functioning database or the continuous operation of the master DNS cluster, they should continue to operate normally even in the event of an event affecting both the primary and secondary site. Due to the importance of DNS services to the overall stability of the Internet, satellite clusters have been designed to operate nearly indefinitely even without any contact from centralized administration
- All data is backed up frequently. Physical and logical database backups are performed on a daily basis, and stored both on magnetic tape using state-of-the-art AIT3 tape backup technology and on the NFS filer. Application data is stored both on off-site development systems and is backed up on a daily basis. Tape backups are routinely moved to off-site locations, and data escrow services will be used to ensure that this information is stored and available. In the event of a catastrophic failure affecting both sites, it would be possible to restore data from tape in a relatively straightforward manner. Registry Advantage will use Veritas Net Backup to manage the backup process and to facilitate the speedy recovery of data if needed.
- Registry Advantages systems have been designed primarily using commonly available hardware and software. The Intel x86 hardware used in server clusters are nearly ubiquitous in todays market, and Sun Enterprise hardware is readily available throughout the world. Even in a situation in which both the primary and secondary sites were completely destroyed, it would be possible to rebuild an operational portion of the .org registry infrastructure using relatively common components combined with stored application and database information.
Although Registry Advantage is prepared for the eventuality of having both the primary and alternate sites simultaneously destroyed, and could recover the full operation of the registry to a point in time previously moved off site on magnetic tape, the location of the alternate site and the diversity of the Internet Service Providers used at either site significantly reduce the likelihood of this occurrence. Detailed (re)construction guides and operations manuals will be stored off site along with the magnetic tapes to assist in the rapid reconstruction of the registry operation if such a need should arise, and these are audited on a quarterly basis for accuracy.
The Fault, Configuration, Accounting, Performance, and Security (FCAPS) management procedures in operating the registry are derived from many years of IT operations and management experience, as well as procedures and guidelines taken from the British Office of Government Commerce's Information Technology Infrastructure Library (ITIL) [2] . All of the relevant documentation and systems governing the configuration, capacity, change and release management process is also backed up and stored at the off site location. This can be used for validation of a reconstructed infrastructure as well as providing a baseline for restoring all operational functions in the event of a major disaster where both sites were destroyed.
Registry Advantage has planned extensively for the possibility of losing a single database, or storage subsystem, or hosting facility, or network component, or ISP, or front end server, or cluster, and leverages consistent technical and operational procedures for these scenarios.
For example, the database replication between the active and the standby database servers works by log switching one per minute, archiving those logs to a staging area, and copying them to the standby system so they can be automatically applied to the standby database server (running in recovery mode). This mechanism is virtually identical to the one used for replication to the backup system, although the distance the copy needs to travel before it can be applied to the backup database server is significantly greater. The software framework used to distribute the log files and apply them to the recovery mode database server instance guarantees the proper sequencing and data integrity of the log file applications in both instances.
In addition to the Oracle transaction logs, the same replication process copies the front end systems' logs to the alternate site so they can be used to recover any data lost in the Oracle log transition. The process of recovering the database (transitioning either the standby or the backup database server to become active) includes replaying the front end system logs in addition to the Oracle transaction logs. This decreases the risk of data loss and improves the overall RPO capability.
The operational model used for change management is also key in our recovery capability. All changes to the production applications and infrastructure undergo rigorous stress and regression testing in a Quality Assurance Testing environment, which is a complete functional replication of the production systems. Once QAT testing is completed and approved by an independent testing and quality control team, the changes will be scheduled for release into both the primary and alternate sites. The primary site is validated immediately after the change is deployed. The alternate site will be validated internally on a monthly basis and a full site functionality test and audit, including database instance recovery from both the replicated logs and a randomly selected magnetic tape set, will be performed quarterly.
C17.16. Registry failure provisions. Please describe in detail your plans for dealing with the possibility of a registry failure due to insolvency or other factors that preclude restored operation.
Registry Advantage has practically eliminated the chance of registry failure by thoroughly planning and implementing its systems, processes, and staffing plans. However, to address even the most unlikely risks, Registry Advantage has several addressed the unlikely event of registry failure.
Registry Advantage has built redundancy, back up and security into the registry. This is documented throughout the rest of section C17, in particular in C17.14 and 17.15.
Registry Advantage will use data escrow services to protect data from possible failures including business failures, system failures, natural disasters and sabotage. The data in escrow would be released to ICANN per the terms of the model registry agreement. For further detail, please see Question C17.7. The registry will also encourage registrars to deposit into escrow all registrar data on a similar schedule. But as the registry will have a centralized shared database, including all Whois records listed herein, the registrys escrow commitment will ensure the availability of accurate records in case of possible registrar failure.
As to insolvency concerns, it should not be an issue. The DotOrg Foundation will have resources collected from domain name registrations to support its operations. In the early stages of operations, prior to the receipt of new registrations and renewals revenue, the Foundation may rely on part of the VeriSign endowment, or if need be on outside funding sources, including a guarantee by its sub-contractors. For reference to DotOrg Foundations budget, please refer to and Attachment E1.
Reliable registry operations benefit from the financial stability of Registry Advantage well as the DotOrg Foundation since Registry Advantage is capable of continuing registry operations under reasonable commercial terms in the event that the DotOrg Foundation does encounter insolvency. Registry Advantage can rely, not only on its .org sub-contracting fees, which are projected to cover capital expenditures and operating costs, but also on the significant resources of its publicly traded parent company to avoid insolvency concerns. For a description of Register.coms resources, please refer to and Attachment E2, Securities Filings the Register.com securities reports.
[1] RFC 1546 (see http://www.xyweb.com/rfc/rfc1546.html)
[2] http://www.ogc.gov.uk/itil/, which defines Service, Incident, Problem, Configuration, Change, and Release Management as independently qualitative entities.